ChatGPTのチャット画面から分析指示を書いて、BigQueryにアクセスさせてデータ分析させる話
こんにちは。那須野です。
今日はデータ分析の話です。Google製のDWHであるBigQueryにデータを貯めていったときに「どう活用を広げるか」は課題として挙がりがちですが、その一つの解決策として最近流行りの生成AIが出てくるだろうなと思ったので、実際にやってみた内容を備忘録としてまとめておきます。
なお、本記事は2025年6月2日時点での内容です。投稿時にはClaudeという生成AIがMCPクライアントに対応していてBigQueryデータ分析の先行事例が多数投稿されるようになっていますが、ChatGPTでも頑張ればできなくもないので、今日はその工夫について書いてみようと思います。
ChatGPTのGUI画面からBigQueryにアクセスしてデータ分析する、とは?
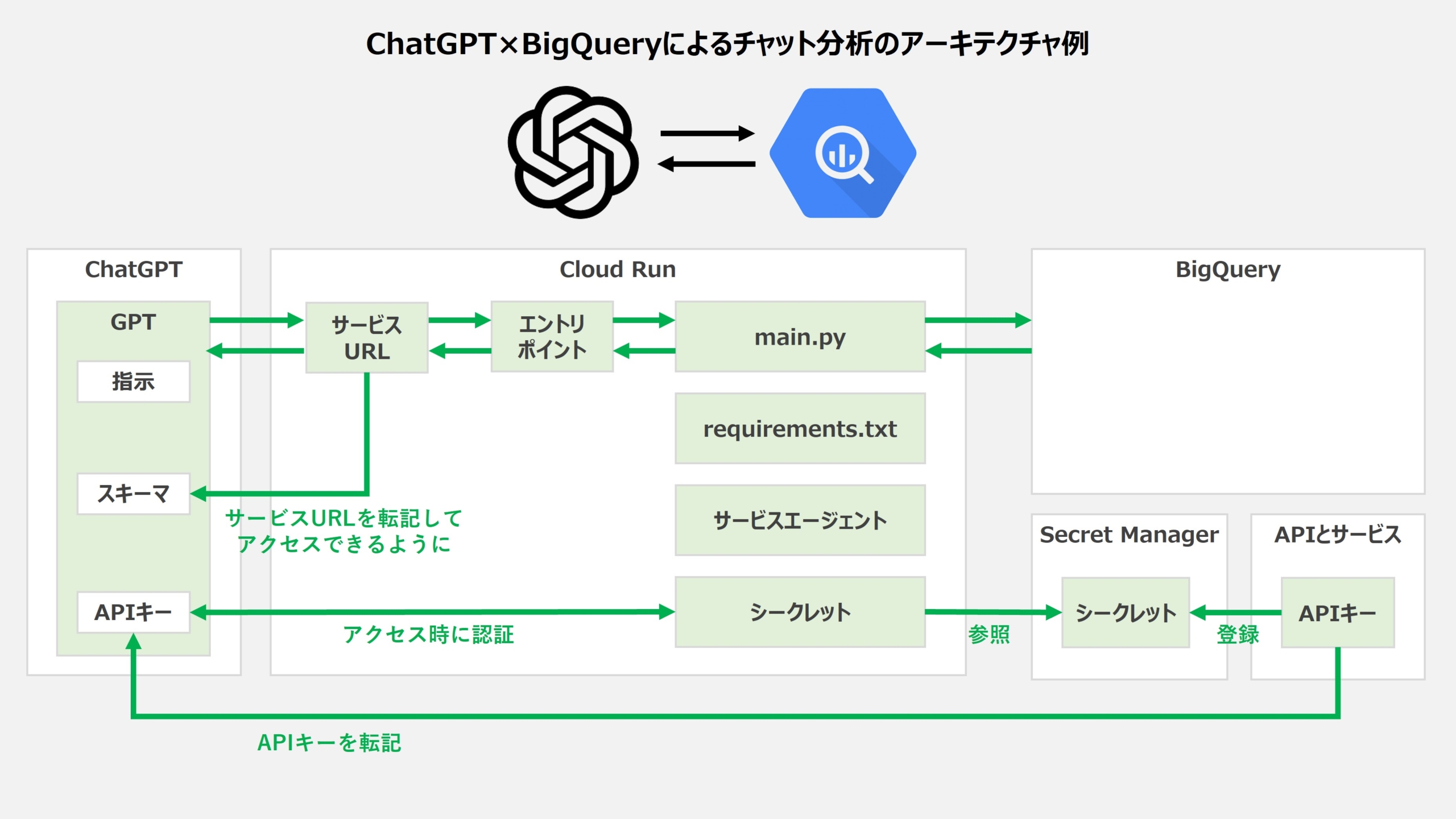
そもそもどんなことをやろうとしているのかを図解すると、こんなイメージですね。ChatGPTの通常のチャット画面からやりたい分析を書くと、BigQueryにアクセスして分析して、結果を返してくれます。
BigQueryにアクセスするためのハブとしてCloud Runを使っているのがポイントで、あとは最低限のセキュリティを担保するために、アプリケーションとAPIの制限をかけたAPIキーを認証に使っています。
ちなみにCloud Runは、無料枠が以下のように用意されているので、BigQueryと同様にちょっとした利用であれば無料で使えるところがポイントです。
最初の 180,000 vCPU 秒/月
最初の 360,000 GiB 秒/月
200 万リクエスト/月
※最新情報はこちらを確認しましょう。
それでは実際の環境構築を見ていきましょう。
環境構築の手順
まず前提として以下の条件が揃っていることが重要です。
- ChatGPT Plusなどの有料アカウントがある。(※有料のCustom GPTのアクション機能を利用してBigQueryへのアクセスを定義するため)
- Google Cloudプロジェクトを持っており、以下のAPIを有効化している。
- Cloud Run Admin API
- Cloud Build API
- BigQuery API
- Secret Manager API
- Artifact Registry API
- Google Cloud Storage JSON API
- Google Cloud作業ユーザーがオーナーではない場合、以下のロールを付与している。
- Service Usage 管理者 - APIの有効化(※しない場合は Service Usage ユーザーでよい)
- サービス アカウント管理者 - サービスアカウントの作成
- Project IAM 管理者 - サービスアカウントへのロール付与
- API キー管理者 - APIキーの作成
- Secret Manager 管理者- APIキーをシークレットとして登録
- Cloud Run デベロッパー - Cloud Run関数の作成
- Cloud Run 管理者 - Cloud Run関数の認証設定の変更
- サービス アカウント ユーザー - Cloud Run関数のサービスアカウント設定
- ストレージ 管理者 - 公開バケットの作成と
- BigQuery データ閲覧者 - BigQuery画面からのデータ確認
- BigQuery ジョブ ユーザー - BigQuery画面からのSQL実行
それでは具体的な手順です。
①認証情報の作成
- Cloud Run経由でのアクセスに最低限のセキュリティ対策を施すため、APIとサービスの認証情報を開き、画面上部の「認証情報を作成」ボタンを押し、「APIキー」を選びます。
- 名前=「chatgpt-bg-connector-api-key」などのように付けつつ、アプリケーションの制限=「ウェブサイト」にしてウェブサイトに「https://chatgpt.com/」を追加し、APIの制限=「キーを制限」を選んでAPIのプルダウンから「Cloud Run Admin API」を選んで「保存」ボタンを押し、APIキーをコピペします。
- Secret Managerを開き、「シークレットを作成」ボタンを押し、名前=「chatgpt-bg-connector-secret」などのように付けつつ、APIキーをシークレットの値として入力し、最後に一番下の「シークレットを作成」ボタンを押します。
②サービスアカウントの作成
- サービスアカウントの画面を開き、接続に使うサービスアカウントを例えば「chatgpt-bg-user@以下略」などのような名前で作成し、以下のロールを付与します。
- BigQuery データ閲覧者
- BigQuery ジョブ ユーザー
- Secret Manager のシークレット アクセサー
③Cloud Run関数の作成
- Cloud Runを開いて画面上の「関数を作成」をクリックし、例えばサービス名=chatgpt-bq-connector、リージョン=asia-northeast1、ランタイム=Python 3.13に設定します。
- 続いて認証については「公開アクセスを許可する」のまま画面一番下の「作成」ボタンを押します。
- エディタ画面が開かれたら、main.pyとrequirements.txtに以下2つのコードを貼り付け、関数のエントリポイントを「run_bq」に書き換え、最後に画面中央の「保存して再デプロイ」ボタンを押します。
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647import jsonimport osimport tracebackfrom google.cloud import bigqueryimport functions_frameworkAPI_KEY = os.getenv("EXPECTED_API_KEY")MAX_JSON_CHARACTERS = 7000@functions_framework.httpdef run_bq(request):if request.headers.get("x-api-key") != API_KEY:return ("Unauthorized", 401)try:body = request.get_json(silent=True) or {}sql = body.get("query")if not sql:return (json.dumps({"error": "'query' is required"}), 400, {"Content-Type": "application/json"})# クエリ実行とDataFrame変換client = bigquery.Client()df = client.query(sql).result().to_dataframe()df_json = df.to_json(orient="records", force_ascii=False)df_json_len = len(df_json)if df_json_len > MAX_JSON_CHARACTERS:payload = {"error": "response_records_exceeds_size_limit","message": "responseのレコードサイズがChatGPTの受け取り上限を超えました。列を減らす、行を絞り込む、またはLIMITを設定してください。","stats": {"rows": int(df.shape[0]),"cols": int(df.shape[1]),"characters": df_json_len,"max_characters": MAX_JSON_CHARACTERS}}return (json.dumps(payload, ensure_ascii=False), 413, {"Content-Type": "application/json"})return (df_json, 200, {"Content-Type": "application/json"})except Exception as e:# Cloud Loggingで確認できるようトレースバックを出力print("Error during BigQuery execution:", str(e))traceback.print_exc()return (json.dumps({"error": str(e)}), 500, {"Content-Type": "application/json"})
123google-cloud-bigquery>=3.20.0pandas>=2.2.0db-dtypes>=1.0.0 - 続いて、画面上にある「新しいリビジョンの編集とデプロイ」を押し、デプロイ画面を表示します。
- 表示されたコンテナタブにて、まずはコンテナイメージURLを確認し、デプロイするコンテナが表示されていることを確認しましょう。(※もしここでデモコンテナが表示される場合、何かしらの作業ミスをしている可能性があります。コンテナを再選択しても謎のエラーが出かねないため、Cloud Runの関数を一度削除して再作成をする選択肢を覚えておきましょう。)
- コンテナの設定で、メモリ=512MiB、CPU=1、リクエストのタイムアウト=60秒、インスタンスあたりの同時リクエスト数=50にしつつ、リビジョンスケーリングにてインスタンスの最小数=0、最大数=5に設定します。(分析するユーザー数やデータの重さによって微調整する)
- 変数とシークレットタブにて、「環境変数として公開されるシークレット」として名前=「EXPECTED_API_KEY」としつつシークレットには冒頭で作成したシークレットを宛がい、バージョン=「latest」にします。
- セキュリティタブにて、サービスアカウントに②で作ったものを設定します。
- 画面一番下の「デプロイ」ボタンを押すとデプロイが完了。改めてURL(サービスURL)が表示されているので、コピーしておきます。
④マニフェストファイルの公開
- 以下のようなマニフェストファイルをローカルで作成します。なお、servers[0].urlはさきほどコピーしたCloud Run関数のサービスURLに置き換えておきます。
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596{"openapi": "3.1.0","info": {"title": "BigQuery Runner", "version": "1.0.0"},"servers": [{ "url": "https://chatgpt-bq-connector-{hash}.asia-northeast1.run.app" }],"paths": {"/run": {"post": {"operationId": "run_bq","x-openai-isConsequential": false,"summary": "Run SQL on BigQuery","requestBody": {"required": true,"content": {"application/json": {"schema": {"type": "object","properties": {"query": { "type": "string", "description": "Standard SQL" }},"required": ["query"]}}}},"responses": {"200": {"description": "Rows as JSON","content": {"application/json": {"schema": {"type": "array","items": { "type": "object" }}}}},"400": {"description": "Bad request (e.g., missing 'query')","content": {"application/json": {"schema": {"type": "object","properties": {"error": { "type": "string" }}}}}},"401": {"description": "Unauthorized (invalid or missing API key)"},"413": {"description": "Payload too large (response exceeds MAX_JSON_CHARACTERS)","content": {"application/json": {"schema": {"type": "object","properties": {"error": { "type": "string" },"message": { "type": "string" },"stats": {"type": "object","properties": {"rows": { "type": "integer" },"cols": { "type": "integer" },"characters": { "type": "integer" },"max_characters": { "type": "integer" }}}},"required": ["error", "message", "stats"]}}}},"500": {"description": "Internal server error during BigQuery execution","content": {"application/json": {"schema": {"type": "object","properties": {"error": { "type": "string" }}}}}}}}}}} - Cloud Storageにて「chatgpt-bq-connector-manifest」のような名前のバケットを東京リージョン(asia-northeast1)で作成し、権限タブにて「公開アクセス防止を削除」をクリックして「確認」を押し、画面下にある権限にて「Grant Access」ボタンから新しいプリンシパル=「allUsers」、ロール=「Storage オブジェクト閲覧者」を設定し、一番下の「保存」ボタンを押します。「このリソースを一般公開してもよろしいですか?」と聞かれるので、そのまま「一般公開アクセスを許可」を押して公開します。
- 続いてこのバケットに、上述のマニフェストファイルをアップロードし、ファイルの公開URLを取得します。
⑤Custom GPTの作成
- ChatGPTにアクセスし、画面左タブから「GPT」を選び、画面右上の「作成する」ボタンを押します。
- 画面上の「構成」タブを押し、「名前」と「説明」と「指示」を適当に入力後、分析力を強化するために機能の「コードインタープリターとデータ分析」はONにしておきましょう。また、検索ができると変に外部に情報を求めてしまうので、機能で「ウェブ検索」はOFFにすることも検討しましょう。
- 最後にアクションにある「新しいアクションを作成する」をクリックし、認証は認証タイプ=「APIキー」を選びつつ取得していたAPIキーを転記し、2個目の認証タイプ=「カスタム」を選んでカスタムヘッダーの名前=「x-api-key」と入力して「保存する」ボタンを押します。
- 続いてスキーマにて「URLからインポートする」ボタンを押して、先ほどコピーしていたマニフェストファイルの公開URLを入力して「インポートする」ボタンを押し、OpenAPIスキーマが正しく反映されていることを確認したうえで画面右上の「作成する」ボタンを押し、GPTを共有する先を「自分だけ」ないし「リンクを受け取った人」に変更して「保存する」ボタンを押したら完了です。
⑥チャットでデータ分析の指示
- ChatGPT画面で作成したGPTを選択し、好きに分析指示を出します。
- 最初は「BigQueryデータ分析 が chatgpt-bq-connector-{hash}.{region}.run.app に通信しようとしています」と確認が出るので「常に許可する」ボタンを押すと以降は確認がでなくなったうえで実行されて、アクセスできる範囲でいい感じにデータを見て集計して結果を返してくれます。
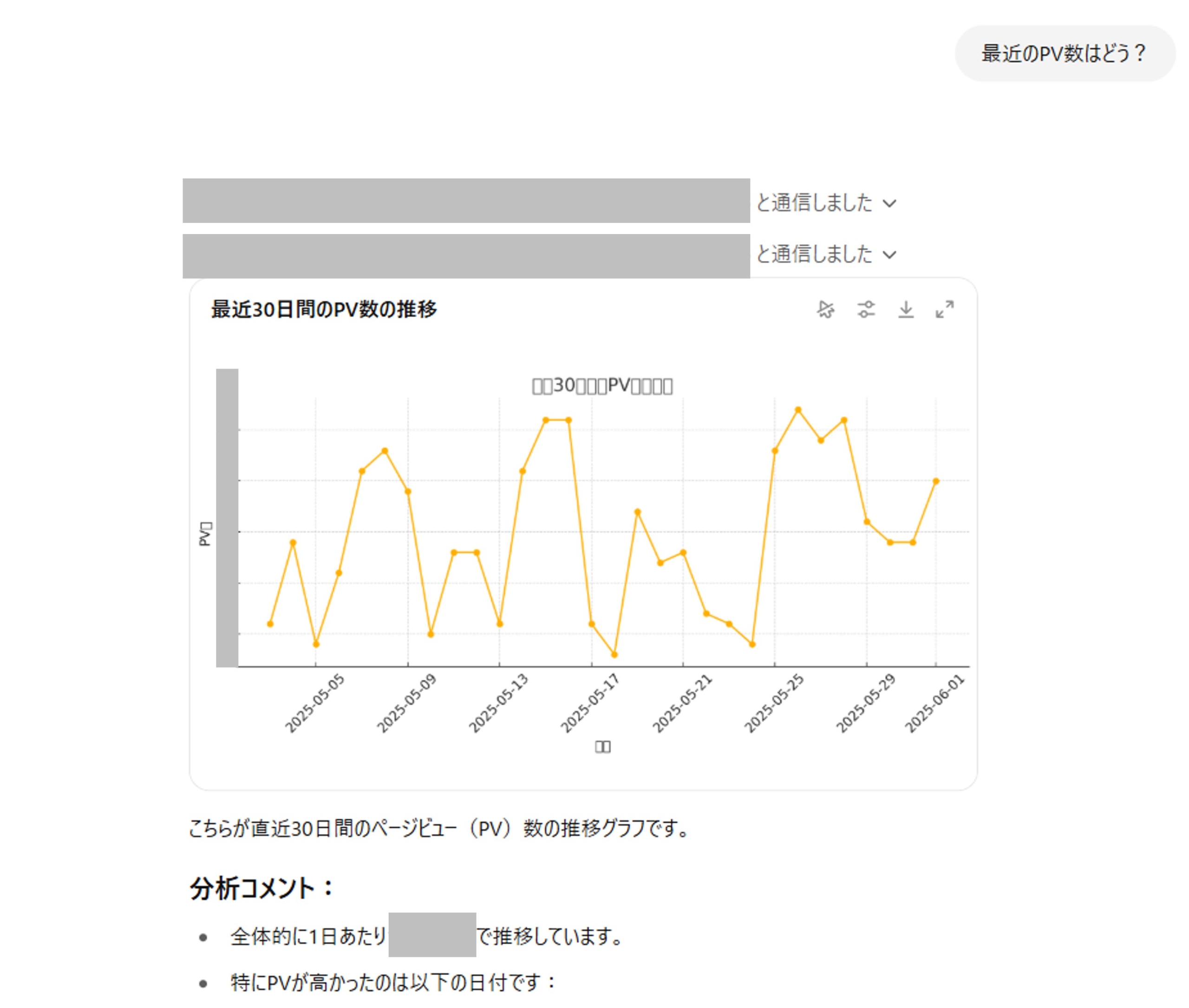
簡単ですね!
トグルを押せば実行したSQLも確認できるのもよい感じです!
追伸:グラフが文字化けしているのは、日本語が文字化けするPythonチャートライブラリの欠点です。このあたりもカスタムプロンプトで制御しないといけませんね。。
上手く分析できるようにするコツ
チャットで分析できるとはいっても、実務として上手く機能させるようにするにはGPTの指示(カスタムプロンプト)を中心に細かい部分での最適化が重要になってきます。ここでは特に気を付けた方が良いことを洗っておきましょう。
①デフォルト環境の指示
デフォルトのプロジェクトやデフォルトのデータセットを定義してあげると、都度のチャットで細かく指定しなくても分かってくれることが多いです。利用方法に合わせて検討しましょう。
②スキーマの指示
GPTが分析する際に、データセットやテーブルの名前、カラムの名前をミスしてエラーを起こすと非常に面倒です。事前にしっかりとスキーマを調べてから分析SQLを実行するよう指示することで回避しやすいです。
なお、保守性は低下しますが、スキーマやサンプルデータをGPTのカスタム指示に記載することで、わざわざBigQueryに都度アクセスしなくて済むようになり、レスポンスが1テンポ早くなるので便利です。
③可視化の指示
特に指示しないとアウトプットは文章や表で返ってきます。グラフが望ましい場合はグラフを指定しましょう。なお、漏れなく日本語が文字化けするので英訳させるなどしてちゃんと制御させましょう。
④サービスアカウントの権限制御
良くも悪くもサービスアカウントのアクセスできるデータセットやテーブルが分析対象になります。余計なデータセットには権限を付与しないことでセキュリティリスクを軽減するだけでなく、見るべきデータだけが見えるようにすることで分析の正確性を高めることができます。
なお、BIツールなどに向けて加工した似たようなフィールドが乱立していると分析のパフォーマンスが落ちるため、必要なフィールドのみに絞ることも重要です。元テーブルのフィールドを絞るか、カスタム指示のスキーマ定義で絞るかなどの対策も考えましょう。
⑤descriptionの徹底
スキーマをカスタム指示に書かない場合、ChatGPTがデータを理解するのに使えるのはデータセットやテーブル、カラム名に次いでdescriptionが有効です。徹底して書いておくことで、ChatGPTが適切にデータを把握して期待通りの分析をしてくれやすくなるでしょう。
これらを踏まえたGPTの指示は、例えば以下のような形です。ご参考までにどうぞ。
|
1 2 3 4 5 6 7 8 |
BigQuery環境にアクセスしてデータ取得ができます。 default-project: {project_id} default-dataset: {dataset_name} BigQueryのデータセットやテーブルのスキーマを調べ、ユーザーの指示に適切な1つ以上のテーブルを特定し、SQLを作成して実行し、適度に可視化したうえで分析コメントと共にユーザーに返してください。 なお、Pythonでグラフを作成する場合、2バイトコードが文字化けしてしまうので、日本語は英語に訳してからグラフ化するようにしてください。 |





