Dataformによるデータパイプラインの構築と運用の進め方【基本の総集編】
こんにちは。那須野拓実です。
Dataformでデータパイプラインを作るぞというときに、一通りの流れが分かるような資料があると便利だなと思ったので書いてみます。
主な内容としては、実際の構築作業の流れを洗いつつ、人によって諸説あるコーディングスタイルを確認したうえで、運用作業の流れを洗っていき、最後におまけとして開発環境を用意する方法についても確認します。

Dataformの構成
そもそもDataformとは何かの説明について昔の記事に説明を譲りますが、Dataformの構成がどのようになっているか、どういったオブジェクト概念があるかは再確認しておきたいです。
昔の記事からの抜粋したイメージがこちらです。これを押さえたうえで、実際の作業の流れを見ていきましょう。
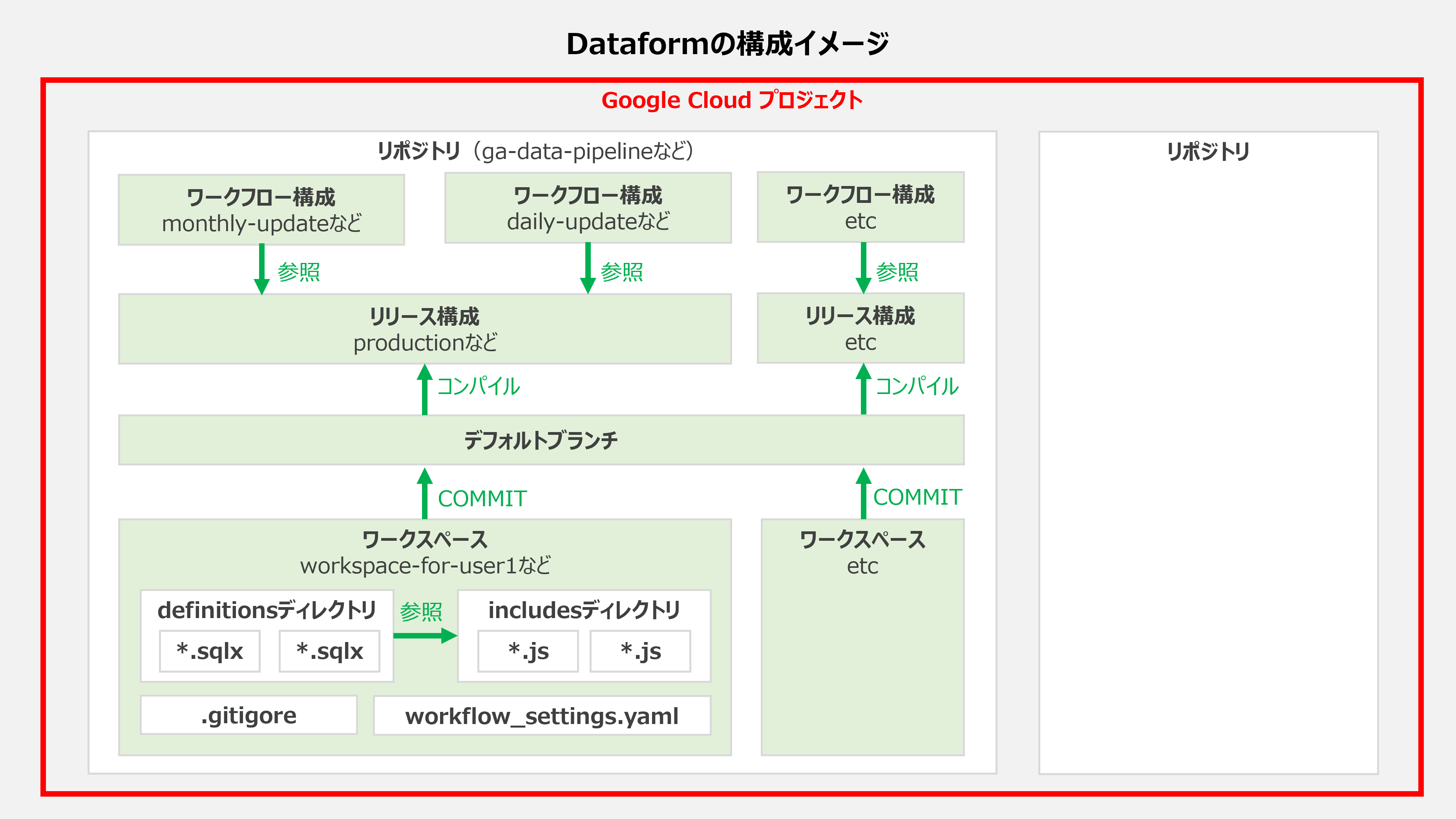
構築作業について
Dataformで実装するうえで、まずは以下6点を注意事項として頭に入れておきたいです。
構築作業の6つの注意点
- ディレクトリの区別
- Googleのベストプラクティスに準拠し、output, intermediate, sourcesなどのディレクトリを設定して、データソースを区別しましょう。
- sources - 元データとなる入力テーブルの定義。
- intermediate - 出力テーブルを作るための、データ変換途中の中間テーブルの定義。変換が終わったら削除して構わないかどうかがoutputかどうかとの区別の基準。
- output - データ変換で最終的に出力されるテーブルの定義。
- Googleのベストプラクティスに準拠し、output, intermediate, sourcesなどのディレクトリを設定して、データソースを区別しましょう。
- ref関数の使用
- SQL内でref関数を使って、Dataform上でデータリネージ(COMPILED GRAPH)が閲覧できるように実装しましょう。
- config.type:'operations'の場合はref関数が使えないので、config.dependencyの明示をしましょう。また、プロジェクトによっては、コンパイル変数を駆使して可用性を担保しましょう。
- アクションタグの設定
- SQLXファイルに実行タイミングごとにアクションタグを設定して、整理整頓しましょう。
- アクションタグの名前は、2桁の連番+アンダーバー+端的なアクション名が推奨です。連番をつけることで、アクションタグが一覧で綺麗に並びます。
- 差分処理の実装
- DATEパーティショニングやインクリメンタル処理などを適宜実装しましょう。
- 運用段階でのSQL書き換え不要を目指す
- SQLの日常的な書き換えは負荷が高く、ミスを生みやすいです。運用段階のワークフローは、SQLエディタは開かずに [リリースとスケジュール] の画面のみでワークフロー作業ができることを目指しましょう。
- 開発環境の検討
- ミッションクリティカルなプロジェクトであったり、チームでの開発であったりする場合、開発したデータパイプラインのテストは本番環境ではやらず、開発用の環境を別途用意した方が良いです。
- 開発環境を用意する場合は環境切り替えができるSQLにしておく必要があるので、用意する場合はなるべく早くから考慮しておいたほうがよいです。詳しい方法については、末尾の「おまけ:開発環境のための実装」を参照してください。
そのうえで、具体的な構築作業の流れは以下をイメージしましょう。
具体的な構築作業の流れ
- データリネージの設計
- SQLを書き始める前に、データリネージを書いて全体の流れを把握しましょう。テーブル名、レコード単位、主要指標は必須とし、できればSQLのイメージを第三者と擦り合わせて解像度を高めましょう。
- SQLの記述
- 注意事項に気をつけながら、SQLを書いていきましょう。Compiled Graph(Dataformのデータリネージ機能)を見て全体感を把握しながら進めましょう。
- SQLで想定される結果を概ね把握しておき、正しい結果が出ているかを作業者が適切な頻度で確認しながら進めましょう。
- SQLのレビュー
- SQLをテスト環境で実行し、想定される結果になっているかレビューしましょう。
なお、原則としてレビューはSQLを書いた人以外にて行いましょう。
- SQLをテスト環境で実行し、想定される結果になっているかレビューしましょう。
- COMMIT
- デフォルトブランチにCOMMITしましょう。
- リリース構成の作成
- デフォルトブランチを参照したリリース構成を作りましょう。
その際、プレフィックスやサフィックス、コンパイル変数などは必要に応じて設定しましょう。 - なお、意図しない更新を防ぐため、リリース構成自体の更新は原則として「オンデマンド」とします。
- デフォルトブランチを参照したリリース構成を作りましょう。
- ワークフローの作成
- 自動ワークフローと手動ワークフローに分けて考えるのが鉄則です。
- 実際にリリース構成を参照したワークフローを作り、実行タイミングを定義しましょう。
その際、原則としてアクションタグによる指定を行い、設定をシンプルにしましょう。
コーディングスタイルの基本
実際に構築作業を行う際、まずはDataformでデータパイプラインを作ろうとしたときに最初にぶつかるであろう、コーディングスタイルの基本中の基本を見ていきます。
人によって諸説あるところですし、あくまで現時点での個人的な見解なので、ご留意のうえお読みください。
変数の表記記法
→スネークケースで書く。
変数を作るときにどの表記方法を使うかは人によって判断が分かれるところですし、データソースによっては元から決まっていることもありますが、やはり揃えられるなら揃えたいところです。
データベースによっては大文字小文字を区別しない点を鑑みるに、やはりスネークケースでまとめておくのが無難でしょう。なお、データソースとなるテーブルはスネークケースにならない場合はあるので、それらは妥協します。
句の大文字小文字
→大文字に揃える。
SQLではSELECT句やWHERE句などの句は大文字で小文字でも機能します。なので、人によってどちらで書くかに違いがあったり、人によっては敢えて揃えずバラバラということもあるでしょう。
ただし、前述の通り変数をスネークケースで揃えた場合、句を大文字に揃えることで変数と句の区別がパッと見で判断しやすくなるため、句を大文字にする方がよいでしょう。
タブの幅
→2個に揃える。
コーディングをする際は構造を分かりやすくするためにタブを使いますが、タブの幅がスペース相当で2個なのか4個なのかは人によって判断が分かれるところでしょう。
この点について、Dataformでは初期設定が2個であるため、原則として2個にするのが無難でしょう。
変数のカンマ区切り
→行末に置く。
変数などカンマ区切りにする場合、変数ごとに改行するのはほぼほぼ全員がやっていることかと思いますが、カンマを行末に置くか行頭に置くかは微妙に好みが分かれるところだと感じます。
ただ、オーソドックスなやり方としてはやはり行末に置く形でしょうし、Dataformのサンプルもそうなので、行末にカンマを原則としましょう。
|
1 2 3 4 5 6 |
SELECT column_a, column_b, column_c FROM {input_table} |
同一行にてコロンやカンマの後が続く場合
→半角スぺースを入れる。
可読性向上のため、コロンやカンマの後に同じ行で続く場合は半角スペースを入れましょう。
|
1 2 3 4 5 |
config { type: 'table', description: 'Sample table definition is here.', tags: ['tag1', 'tag2', 'tag3'] } |
文字列化のクオテーション
→シングルクオテーションを基本とする。
文字列を表すクオテーションはシングルクオテーション(')とダブルクオテーション(")の2種類あります。どちらを使うかは宗教戦争のような側面があるでしょう。
しかし、ことDataformに限っては、実行詳細を確認するときにシングルだと赤字で強調される一方で、ダブルの場合は黒字のままという仕様があります。分かりやすさ重視で言えば、シングルクオテーションを基本とするのがよさそうです。
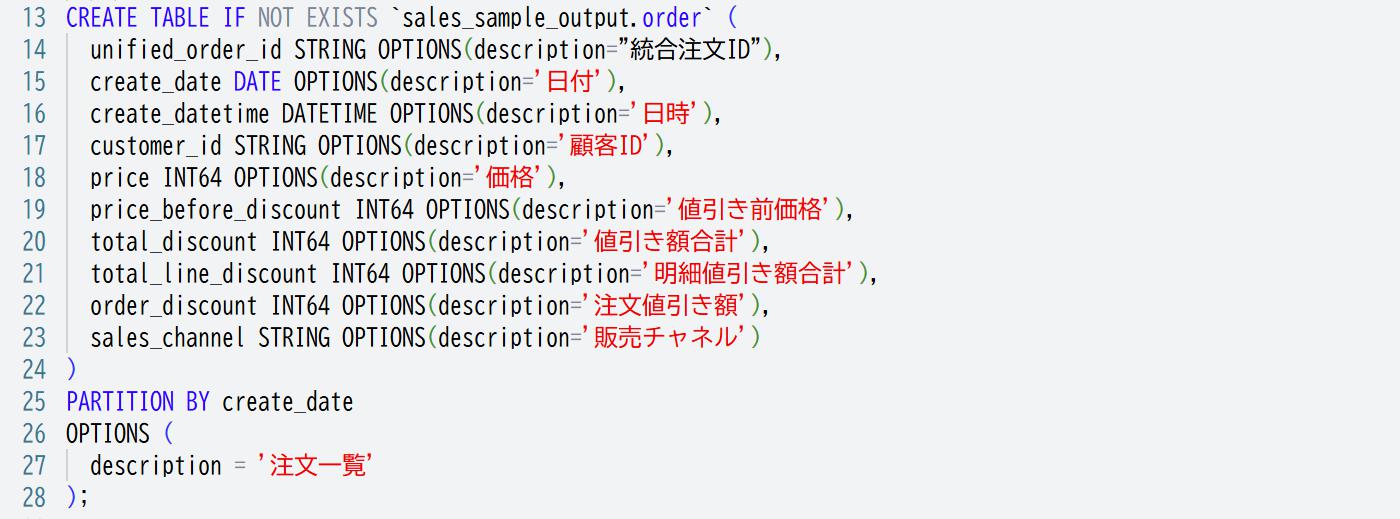
projectとdatasetの定義
→大型プロジェクトなら個別ファイルで明示。それ以外ならデフォルトを駆使しながらsourcesだけ明示する。
project(database)とdataset(schema)の定義を個別のSQLXファイルで書くことを徹底するか、workflow_settings.yamlで適切に書いてあるから省略するかも、人によっては判断が分かれるところでしょう。
作成するテーブル群を元テーブル(sources)と加工テーブル(output)に分けたときに、outputを1つのデータセットで管理できるなら
- outputについてはworkflow_settings.yamlでデフォルトとして設定し、個別には設定しない。
- sourcesについては色々と散らばっていそうなので、個別に設定する。
という使い分けによる省エネが良さそうです。outputが複数のデータセットにわたる大型のプロジェクトの場合、省略する場合としない場合とが混在すると状況把握が難しくなるので全てに書く方が良いと考えます。
nameの定義
→ファイル名を正しく使い、config.nameは極力使わない。
nameについては、デフォルトではファイル名を参照するという仕様がある一方で、もちろんconfig.nameによる明示もできます。
人が読むにはconfig.nameにある方が一貫性があって良い気はしますが、原則としてファイル名=nameとすべきであるし、ズレていると思わぬミスを引き起こすリスクがあることから、ファイル名を正しく使ってconfig上は省略するという運用が望ましいでしょう。
description
→全てのテーブル、カラムにつける。
作成するテーブルやカラムには、原則として全てにdescriptionをつけて、他の人がBigQuery上でスキーマ定義を見て最低限分かるようにしましょう。
運用作業について
続いて運用作業です。
SQLを書き換えなくてよいワークフローが完成しているという前提で、運用段階で発生する主な作業を9つに整理しました。
- データの手動投入
- 手動ワークフローの実行
- 自動ワークフローの実行監視
- データのモニタリング(データ品質の担保)
- クエリのモニタリング(コストとパフォーマンスの最適化)
- マスターデータの更新
- ユーザー問い合わせの対応
- 利用状況のトラッキングと体制見直し
- 定期的な改修対応
なお、できることが多岐にわたり、かつやればやるほど管理コストが上がっていくため、実務上は現場に求められるSLAをもとに費用対効果に見合う運用として再設計する必要がある点には留意します。
それでは1つずつ見ていきましょう。
1.データの手動投入
全てのデータが自動同期されていれば不要ですが、実際には少なくないプロジェクトでデータの手動投入が発生します。その場合は定期的に、指定されたデータを指定された場所(クラウドストレージやスプレッドシートなど)に手動で格納する運用を設計しましょう。
なお、その後は、自動ワークフローの実行による反映を待つ場合と、手動ワークフローを速やかに実行する場合とに分かれます。現場の必要とするスピード感に合わせた運用を設計しましょう。
2.手動ワークフローの実行
前項のデータの手動投入の後のデータ更新も含め、他の手作業のワークフローとの連携があって実行タイミングを定義しづらいデータ更新は手動での実行となります。
手作業はリスクが大きいため、実行履歴を残して漏れなく作業できていることを確認できるようにし、また作業前後の状況をファクトとして最低限確認できるよう作業結果を残しておくようにしましょう。
3.自動ワークフローの実行監視
Dataformであれば多くのワークフローは自動で実行されるわけですが、常に正しく実行されるというわけでもありません。時にはエラーが起きて失敗します。重要なのは、エラーが起きた際にその事実を速やかに把握し、状況を的確に捉えたうえで、問題があれば原因究明し、必要に応じて解決を行えるようにしておくことです。
まず、ログベースの指標にてエラー数を検知できるようにしましょう。具体的には、指標タイプ=Counterにて、フィルターにてBigQueryのエラーないしDataformの定期実行エラーを検知できるようにしましょう。
|
1 2 3 4 5 6 7 8 9 |
# BigQueryのエラー resource.type="bigquery_resource" protoPayload.jobInsertResponse.resource.jobStatus.errorResult:* # Dataformの定期実行エラー resource.type="dataform_workspace" protoPayload.serviceName="dataform.googleapis.com" protoPayload.metadata.triggerType="SCHEDULED" protoPayload.response.state="FAILED" |
その後しばらくすると指標が生成され、Metric Explorerにてグラフを確認できるようになります。
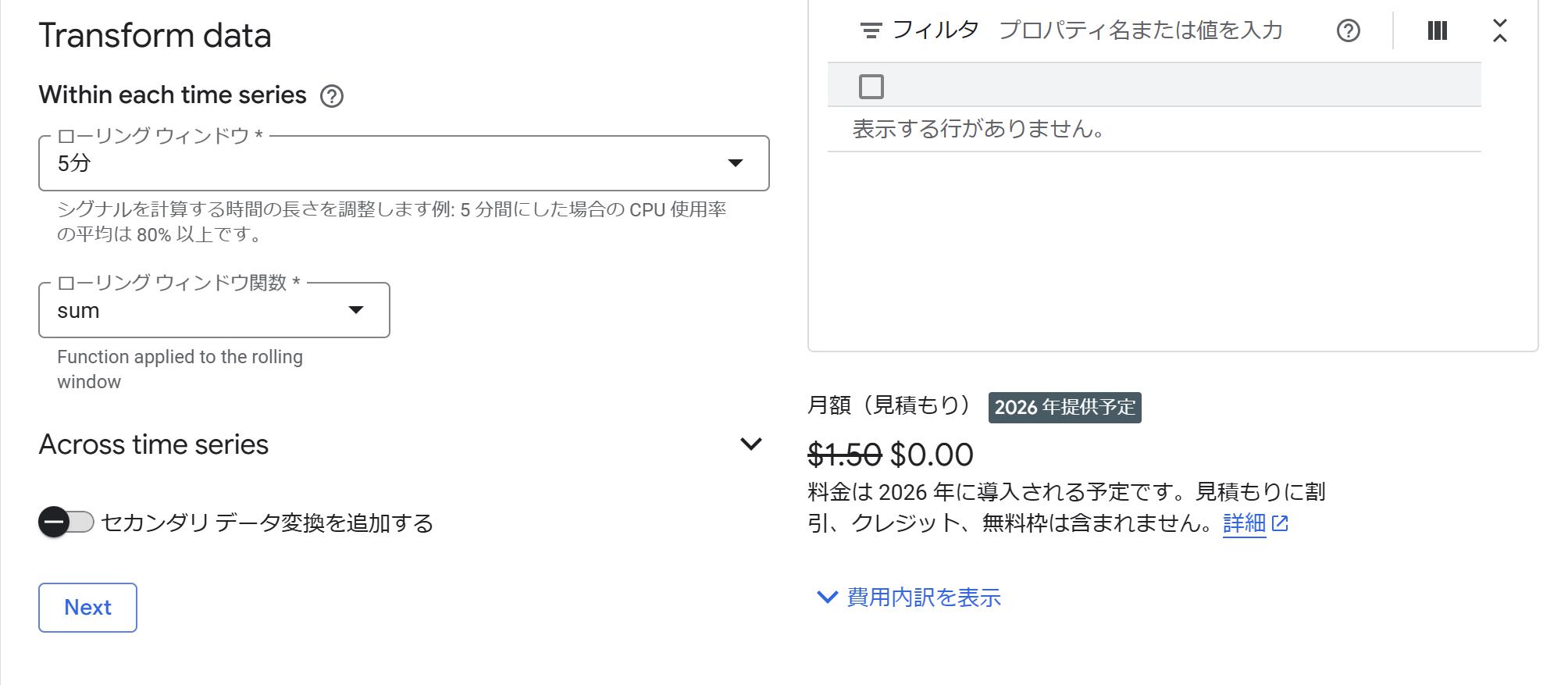
続いて通知が来るようにするために、アラートにてポリシーを作成しましょう。例えば先ほどのbigquery_error_countでは、ローリングウィンドウ=5分、ローリングウィンドウ関数=SUM、Condition Types=Threshold(閾値)、Alert trigger=任意の時系列の違反、しきい値 0 より上に設定し、最後に通知先と通知件名、そしてアラートポリシーの名前を設定して完了です。
ちなみに通知先はGoogleアカウントのメアドが基本ですが、Google ChatやSlack、Webhooks、SMSなども選べるので、状況に合わせて利用するのと、リスク防止の観点では複数のチャネルを設定するとよいでしょう。
また、エラー通知があった場合に、誰がどのように対応するかについても重要です。組織としての妥当なSLA(サービス・レベル・アグリーメント)を定義したうえで、体制を整えておきましょう。
なお、Metric Explorerは2025年3月時点では無料で使えるようですが、2026年からはお金がかかるようです。画面を見た感じだと月1.5ドルなので留意しておきましょう。
4.データのモニタリング(データ品質の担保)
ワークフローがエラー無く動いてダッシュボードにデータが表示されていても、データソースに問題があるとまともに使うことができません。たとえば異常値が入って集計値がまともに見れなくなったり、欠損値が入って推移や変化率が見えなくなったり、データが重複したために指標が水増しされたりなどです。
こういった問題を検知するには、現場の必要とするSLAを考慮して以下の3点でのチェックを検討しましょう。一般的には上のものほど採用率が高いと思います。
- assertionsの設定 - Dataformのパイプライン構築時にassertionsを設定して、ID系のカラムを中心に少なくともuniqueKeyやnonNullなどはチェックしておきましょう。
- リスクレコードの定期チェック - 主要数値については珍しい順(例えば売上であれば高い順など)にソートして生データを可視化し、月に1回などの頻度で確認し、異常値がないか定期確認しましょう。
- 集計指標のチェック - 主要な集計指標について、急激な変化があったときに問題がないか調べるアクションを取れるよう、通知が届く設定ができるとよいです。ただし、Looker Studioには異常検知系の機能がなく、無理やりやろうとすると以下のAやBのような無理やりの実装になり、採用を見送ることが多いです。Cのような代替案を取るのか、もしくは妥協するのかなどの判断をしましょう。
- Cloud Scheduler × Cloud Functionsでの実装 - Cloud SchedulerでCloud Functionsを定期実行してSQLでBigQueryからチェックしたい集計値を取得し、閾値以上の場合にGmail APIなどで通知することができます。
- コネクテッドシート × GASの実装 - BigQueryのチェックしたい集計値のテーブルをコネクテッドシート機能でGoogleスプレッドシートにエクスポートし、GASでデータチェックを実装することができます。
- 目検での確認 - 異常値があるかどうかが端的に分かる集計レポートを作り、目検で定期確認することもできます。Looker Studioの [共有] の [配信のスケジュール] によって定時にレポートをPDF形式でメール送信することで、ある程度簡易的に行うことも可能です。
5.クエリのモニタリング(コストとパフォーマンスの最適化)
ダッシュボードに適切にデータが表示されて使えていたとしても、その効果に見合わないほどのお金がかかりすぎていたとしたら運用としては合格にはなりません。そう、BigQueryは「お金を溶かす」ことがあります。
お金を溶かさないために、差分更新をはじめとした工夫によって「溶かしづらい」データパイプラインを構築することはもちろん大前提ですが、動くデータを集計するパイプラインは問題が起きないか常に監視しておく必要があります。
具体的には、以下の3点を対策しておきましょう。
- 予算アラートの設定 - 課金の中の [予算とアラート] の機能で予算を作成し、想定される費用を超えそうな場合にアラートが送信されるようにしましょう。
- 高額クエリのチェック - BigQueryのジョブエクスプローラを月に1回など定期的に確認し、高額なクエリ、つまり処理されたバイト数が大きなクエリがどういったものか確認してみましょう。もし予算的に許容しづらい大きなクエリがあった場合、データパイプラインの見直しを検討しましょう。
- 高負荷クエリのチェック - また同じくジョブエクスプローラでは、処理に時間が長くかかっているクエリも確認しましょう。BigQueryのデータ更新クエリは多少長くても許容できることが多いですが、Looker Studioからのデータ取得クエリが長い場合、現場のダッシュボード表示が遅くなっている可能性があります。データマートの見直しや、Looker Studio備え付けの1GBに加えてBI Engineで追加のキャッシュを予約することも検討しましょう。
6.マスターデータの更新
データ分析ではデータをある程度のまとまりに区切って集計することが多く、現場の意図に合った集計のためにマスターデータ(例えば商品マスターや店舗マスター、URLマスター、組織マスター、従業員マスターなど)を用意しておくことが多いです。ほとんどの場合、これらマスターデータは勝手には更新されてくれないので、現場の動きに合わせた更新業務が発生します。
マスターデータは日常的な更新は発生しないという前提ですが、月に1回や四半期に1回、半年に1回、年に1回などの頻度で発生しうるため、現場のスピード感に合わせた更新体制を整え、またイレギュラーな更新が必要になる際に作業ワークフローも整えておきましょう。
必要に応じて、マスターデータの切り替えをテストできるように開発環境を整えておくことや、マスターデータの参照も開発環境/本番環境で切り替えられるようSQLの実装を工夫しておくことも考えてましょう。
7.ユーザー問い合わせの対応
現場ユーザーからは定期的にフィードバックをもらえるようにしましょう。
というのも、ダッシュボードは現場ユーザーが使ってなんぼなわけで、もし何らかの理由で使えていなくなっているとしたら、データベースやデータパイプラインはただの金食い虫に成り下がるからです。
なお、メアドやチャットなどで問い合わせ窓口を用意すればよいだけではないかもしれません。気軽に言い合える関係でなければ、問い合わせ窓口を用意したところで実際には連絡が来ずに放置されて、そのまま運用がフェードアウトするケースも散見されます。
関係性が出来上がっていないような状態であったり、対象ユーザーが広範にわたる場合は、運用側から能動的にフィードバックを取得しに行く体制を整えることも検討しましょう。
8.利用状況のトラッキングと体制見直し
前項とも関連しますが、使われていないダッシュボードは無意味どころか負債です。そして「ちゃんと使われているかどうか」を確認するには、利用状況をトラッキングする必要があります。
利用状況は、できればレポート単位であったり、できれば部門単位や個人単位でトラッキングできることが望ましいです。以下の3つの方法が考えられますが、実務上は1番で妥協することが多いでしょう。
- GA4利用 - Looker StudioファイルにGA4(Google Analytics 4)のタグを入れましょう。何人がアクセスしているか、どのレポートがたくさん見られているかといった集計値が確認できます。誰がどのレポートを見ているかまでは分からない点に留意しましょう。
- 社内ポータル埋め込み×GA4ユーザーID送信 - Looker Studioファイルを社内ポータルなどに埋め込み、社内ポータルのページでGA4にuser_idを送信することで、誰がいつLooker Studioファイルを見ているかを判別できます。ただし、そもそも多少の実装コストがかかる点と、どのレポートを見ているかを区別することは困難(レポートごとに埋め込みURLを分けるなどが必要)な点に留意が必要な取り組みです。
- Google Adminのログイベント - GoogleアカウントのAdmin権限を持っている(admin.google.comを使える)場合、エンタープライズ以上などのGoogle Workspaceプランであれば [レポート] の [監査と調査] の [Looker Studioのログイベント] を検索することで、どのメールアドレスの人がいつどのレポートIDを見たかのログを分析できます。データとしては完璧ですが、多くの企業ではシステム部門しかアクセスできないと思われます。
9.定期的な改修対応
一度作ったダッシュボードはそのままずっと使い続けられるということはほとんどありません。ダッシュボードを使うなかで「より良いデータ活用に気づく」こともあれば、「現場の状況が変わって別の分析を必要とするようになる」こともあります。そういった変化は定期的に発生するため、ダッシュボードの定期的な改修対応が必要になってきます。
前述の4~8あたりをしっかり取り組んでいれば、改修内容の把握は十分にできるのではないかと思いますが、実際に改修対応をするには、以下のような点に目を配らせておく必要があります。
- 設計書を最新にしておく - 改修では仕様が明快に分かることが重要です。仕様の設計書については最新であるよう更新しておきましょう。なお、設計書はアーキテクチャやデータリネージ、テーブル、ダッシュボードなど、様々な単位で作ることができますが、たくさん作ると更新負荷が高くなり、更新されずに古いままのものが散見されて逆に理解の妨げになりがちです。求められるSLAに合った「更新し続けられる」必要最低限の設計書を意識しましょう。
- 改修履歴を残しておく - 過去の経緯が分かることも重要です。チケット管理ツールやドキュメントツールなどを使って改修の経緯が最低限分かるようにしましょう。
- IAMロールを整理しておく - 複数人が開発を行う場合、誰がどんな権限を持っているか、IAMロールを整理しておきましょう。
おまけ:開発環境のための実装
最後におまけとして、開発環境のための実装について書いてみます。
冒頭に書いたように、ミッションクリティカルなプロジェクトであったり、チームでの開発であったりする場合、開発したデータパイプラインのテストは本番環境ではやらず、開発用の環境を別途用意した方が良いです。
Dataformで開発環境を用意するにはいくつかの方法がありますが、環境を用意する目的感として
- 開発者がテストするときは、開発用のデータセットでSQLが走ってほしい。
- 開発者が複数人いる場合、開発者それぞれのデータセットを用意できるようにしたい。
- 大元のデータソースは本番のものを参照する形式でよい。
- 本番環境での実行はコンパイルしてワークフローとしての実行のみとしたい。
という前提があるのであれば、コンパイル変数の活用で実装が可能です。具体的には以下のようなイメージです。
コンパイル変数による開発環境の手順
- workflow_settings.yamlのdefaultDatasetには、開発者個人がテストする際のデータセットを記述します。コンパイル変数にて開発環境であること、本番環境でのデータセットはどこかを定義します。これで、エディタ上で実行した場合は開発環境で実行できます。なお、開発者が複数いる場合は、{dev_dataset_name}をそれぞれの開発者のデータセットとします。
1234defaultDataset: {dev_dataset_name}vars:ENVIRONMENT: 'dev'PROD_DATASET: '{prod_dataset_name}' - includes/constants.jsにて以下のように出力先のデータセットを定義します。
123456module.exports = {output_dataset:dataform.projectConfig.vars.ENVIRONMENT === 'prod'? dataform.projectConfig.vars.PROD_DATASET: dataform.projectConfig.defaultSchema}; - 各SQLXファイルのconfigにて、includes/constants.jsを参照する形で動的にschemaを設定します。
123config {schema: constants.output_dataset} - コンパイル時に、コンパイル変数にてenvironmentをprodに上書きします。これによって、リリース構成を実行する場合やワークフローとして実行する場合は、本番環境にて実行されるようになります。
この方法の一番のメリットは、やろうと思えばconstants.jsにて出力先のデータセットを複数用意できる点、つまり、outputとintermediateを切り分けられる点です。柔軟性がとにかく高いです。
コンパイル変数による開発環境の注意点
なお、コンパイル変数による開発環境にも2つ注意点があります。
- 開発者が複数いて開発者ごとに開発環境が用意されている場合、デフォルトブランチにPUSHするworkflow_settings.yamlは、その開発者の開発環境が設定されていることになります。そのため、他の人がPUSHしたコードをPULLしたときは、workflow_settings.yamlの開発環境用データセットを書き換える必要があります。
- コンパイル変数による環境切り替えをフル活用する場合、config.type:'operations'にて複数テーブルを1ファイルで作ろうとすると絶対参照が必要になってref参照×コンパイル変数による環境切り替えが機能しません。そのため、1ファイル→1テーブルを原則として中間テーブルも1つのファイルにするようにしましょう。
これらの点には注意しつつ、開発を進めていきましょう。
まとめ
以上、Dataformによるデータパイプラインの構築と運用の進め方ということでまとめてみました。
この記事を読みつつ、以前の記事である2つを読むと、Dataformのスタートをぼちぼち切れるのではないかなと思います。これらの記事がいつかどなたかの参考になれば幸いです。





