Dataformを使ってBigQueryにあるGA4データを加工してLooker Studioで可視化してみた話
こんにちは。那須野拓実です。
本日はデータビジュアリゼーションのお話です。
少量の利用であれば無料で使えてしまうお買い得なデータベースとBIツールの組み合わせであるBigQueryとLooker Studioは、両方ともGoogle Cloudのサービスとして展開されていて実績も知名度も抜群です。
しかし、肝心のデータ可視化を担うBIツールであるLooker Studioは、他のセルフサービス型のBIツールであるTableauやPower BIなどと比較するとデータ加工の自由度が滅法弱いので、データベース側でのデータ加工を余儀なくされるケースが多いです。
それはつまるところSQLを書くわけですが、そのSQLの開発環境ならびに実行環境をどうするかについては好みが分かれるところです。そこで今回は
- なるべくシンプルなアーキテクチャ
- なるべく無料で済ませたい
ということで、BigQueryの中のイチ機能として存在するDataform(データフォーム)という機能について、使ってみた際のざっくりイメージと作業プロセスをまとめてみたいと思います。
Dataformとは?
Dataformを端的に言うと、BigQuery内でのデータ変換をまるっとハンドリングしてくれるツールです。データパイプラインツールだったりデータ変換ツールだったりデータオーケストレーションツールだったりと色々なジャンル名で呼ばれています。
Google Cloudの1サービスであるBigQueryの中の1サービスとして存在し、もちろん100%クラウドネイティブ。すべての作業を(原則として)Webブラウザ上で行い、全てがGoogleの管理するクラウド環境で管理・実行されます。
Google Cloudのサービスとして一般公開されたのは2023年6月9日からなのですが、シンプルだが強力ということで、BigQueryでのデータ変換を管理するうえでのデファクトスタンダードになっていくんじゃないかと勝手に思っています。
ということで次章の使い方に入る前に、Dataformの構成がどのようになっているか、どういったオブジェクト概念があるかをざっと図示してみました。
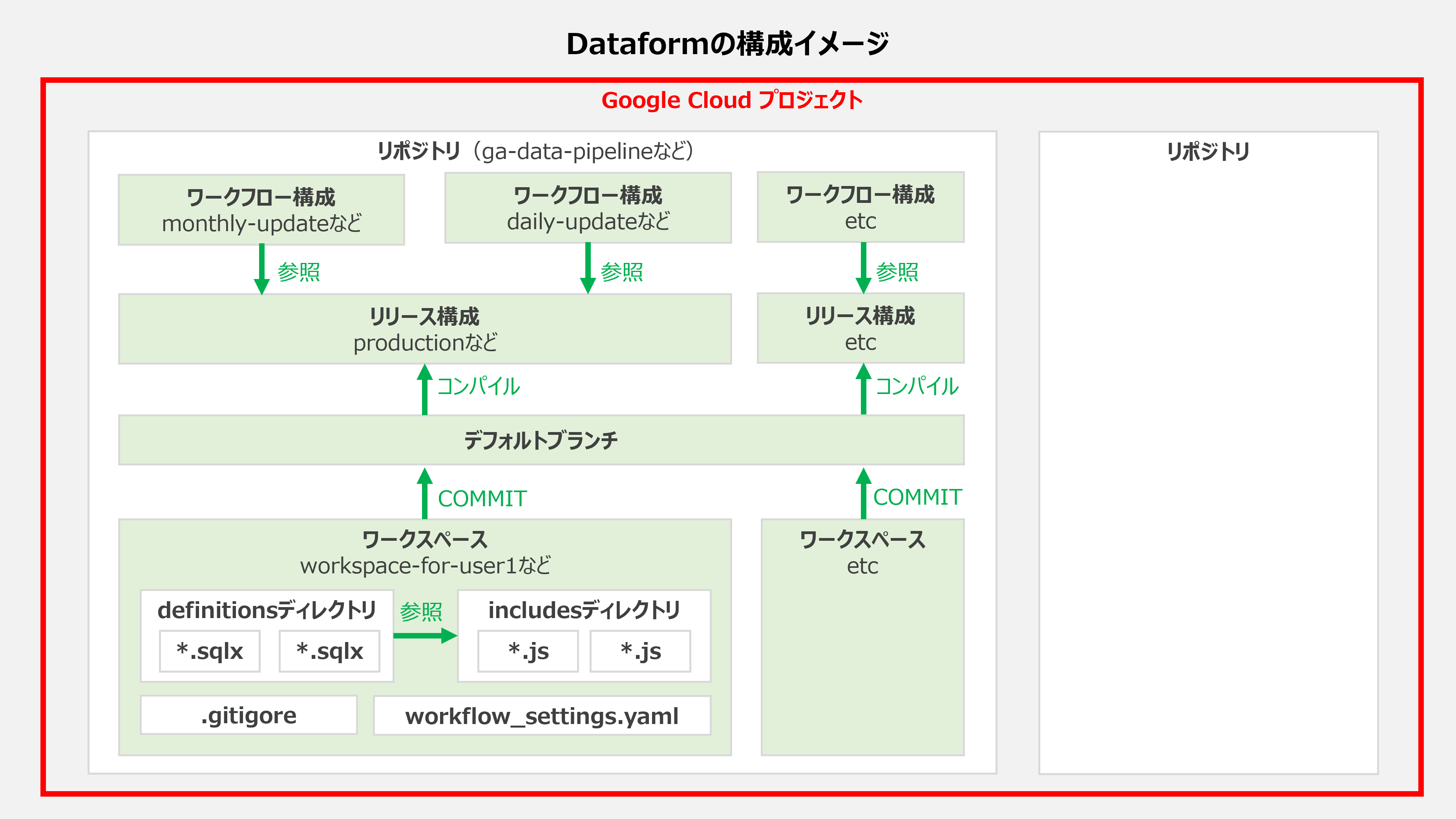
なお、初見で見る場合は分かるようでわからないと思うので、その場合はざっと眺めたうえで次章を読み終わってからここに戻ってくるとよいかもです。
Dataformの使い方とは?
それでは具体的な使い方の流れを見ていきましょう。
Dataformは以下のような流れで利用するのがシンプルで分かりやすいかなと思います。①環境構築→②リポジトリの作成→③ワークスペースの作成→④データ変換の記述→⑤データ変換の実行→⑥データ変換の定期実行の設定→⑦Looker Studioでのデータ参照、という流れで説明していきます。
①環境構築
- Dataform紹介ページにアクセスし、[コンソールへ移動]を押してDataformにアクセスする。
- Dataformが初めての場合は有効化画面が表示されるので、[有効にする]ボタンを押す。
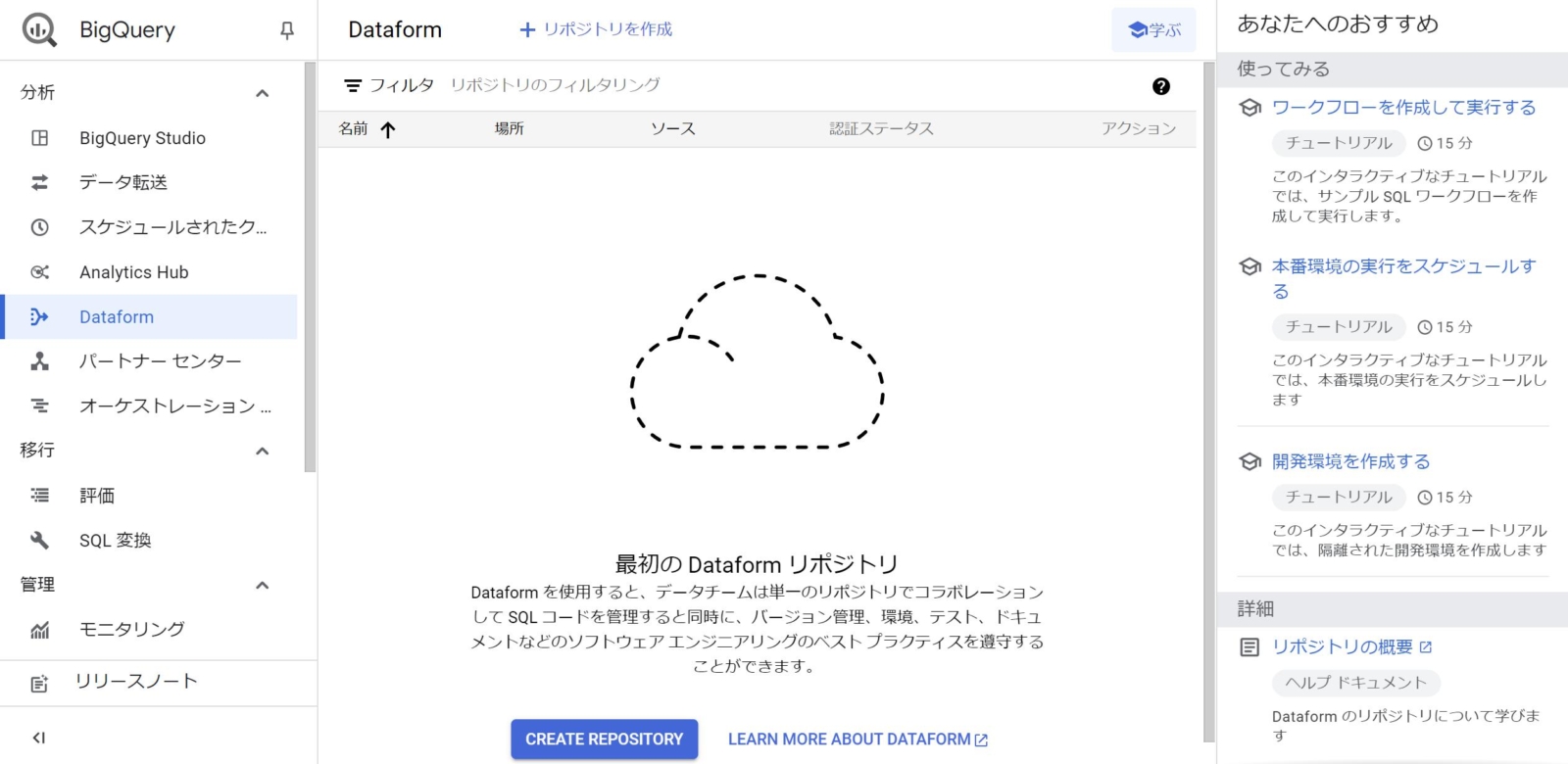
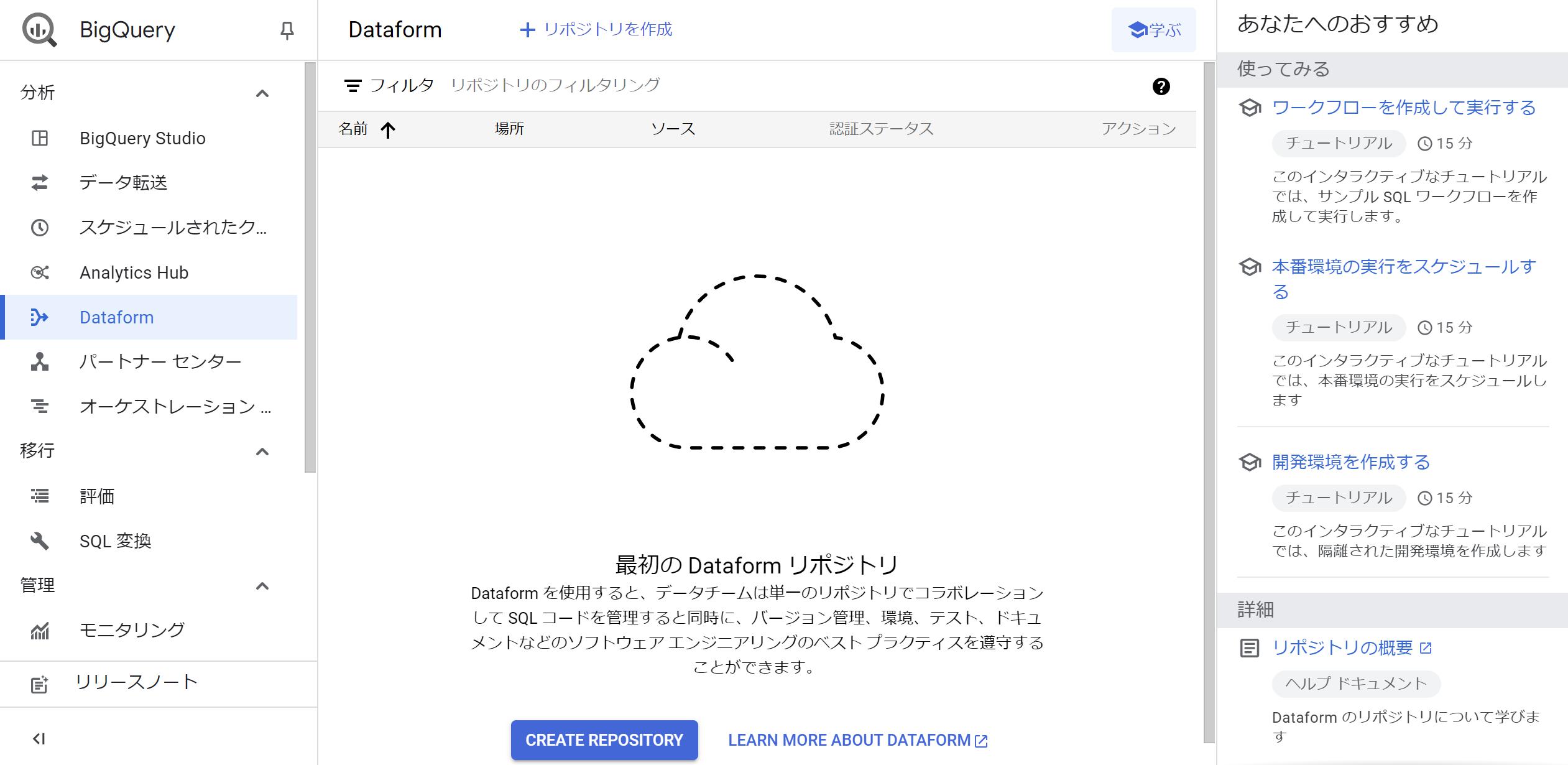
- Dataformが有効化されるとDataformのトップページにリダイレクトされます。BigQueryサービスの1つのタブとして存在していて、ぼちぼち日本語にも翻訳されています。画面右にチュートリアルがあるのも初心者にありがたい仕様ですね。
- なお、今回はDataformの実行にデフォルトのサービスアカウントを使うため、IAMに移動して[]にチェックを入れたうえで[service-YOUR_PROJECT_NUMBER@gcp-sa-dataform.iam.gserviceaccount.com]という名前のサービスアカウントを探し、プリンシパルの編集ボタンを押して以下の権限を追加設定します。
- BigQuery データ編集者
- BigQuery データ閲覧者
- BigQuery ジョブユーザー
- BigQuery データオーナー
②リポジトリの作成
Dataform環境が構築できたら、今回のテスト用にリポジトリを作成しましょう。Gitのリポジトリと同等の概念で、データ変換のプロジェクトごとに作るとよいです。
- Dataformのトップページにて中央上の[リポジトリを作成]ボタンを押し、リポジトリID、リージョン、サービスアカウントを設定し、[作成]ボタンを押します。なお、リポジトリIDは適当な文字列で付けて、リージョンは特に指定がなければasina-northeast1、サービスアカウントは上述のデフォルトサービスアカウントを使います。(※サービスアカウントが表示されないことが稀にありますが、その場合は空白にしておいてよいです。自動的にデフォルトのものが選ばれます。)
- Dataform画面に戻り、[リポジトリに移動]ボタンを押すと、リポジトリ一覧の画面に遷移するので、先ほど作成したリポジトリをクリックします。これで、リポジトリ作成は完了です。
③ワークスペースの作成
リポジトリの中にワークスペースを作成します。ワークスぺースはGitで言うブランチのようなもので、例えば複数人で作業する際に個人ごとにワークスペースを宛がうことができます。
- リポジトリ画面の上にある[開発ワークスペースを作成]ボタンを押し、ワークスペースIDに適当な文字列を入力して[作成]ボタンを押すと、開発ワークスペースができます。
- ワークスペース名をクリックしてワークスペース画面を開き、[ワークスペースを初期化]ボタンを押すと、初期設定のファイルが自動生成されます。ここからが本番です。
④データ変換の記述
ワークスペースの中で、実際のデータ変換を進めていきます。自由度が高いので、Googleのベストプラクティスに準拠しながら作業を進めていきます。今回は、BigQueryに同期しているGA4のデータを変換することを考えてみましょう。
- 初期設定のファイル(definitions配下のfirst_view.sqlx, second_view.sqlx)を削除します。
- definitionsディレクトリに、ベストプラクティスに従って以下の3つのディレクトリを作ります。(※これからこれらディレクトリにSQLXファイルを作っていきますが、どのディレクトリに作るかどうかは成果物に影響しません。)
- sources - 元データとなる入力テーブルの定義。
- intermediate - 出力テーブルを作るための、データ変換途中の中間テーブルの定義。変換が終わったら削除して構わないかどうかがoutputかどうかとの区別の基準。
- output - データ変換で最終的に出力されるテーブルの定義。
- まず、分析対象とするGA4テーブルを定義します。
- sourcesディレクトリを選んで[ファイルを作成]ボタンを押し、ファイルパス「definitions/sources/events.sqlx」を入力して[ファイルを作成]ボタンを押すと、空のファイルが生成されて、エディタが立ち上がります。
- エディタにて以下の内容を記述します。細かい書き方は割愛しますが、GA4のテーブルはテーブルサフィックスで日付ごとに生成されているため、ワイルドカードでまとめて指定します。
123456config {type: 'declaration',database: '{ga4-project-id}',schema: '{ga4-dataset-name}',name: 'events_*'} - 続いて、後々のデータ変換で都道府県を英名から日本語名に置換するように、prefecuturesテーブルも定義しておきます。typeをtableにして、SELECT文を書くことで、テーブルを生成することができます。なお、テーブルの生成先はworkflow_settings.yamlでdefaultDatasetとして定義されたデータセットであり、特にいじっていなければdataformデータセットになります。個別のテーブルで生成先を買えたい場合は、config.databaseやconfig.schemaを明示しましょう。
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354config {type: 'table',name: 'prefectures'}SELECT * FROM UNNEST([STRUCT('Tochigi' AS name_en, '栃木県' AS name_ja),('Tokyo', '東京都'),('Kagawa', '香川県'),('Miyagi', '宮城県'),('Hokkaido', '北海道'),('Aomori', '青森県'),('Iwate', '岩手県'),('Akita', '秋田県'),('Yamagata', '山形県'),('Fukushima', '福島県'),('Ibaraki', '茨城県'),('Gunma', '群馬県'),('Saitama', '埼玉県'),('Chiba', '千葉県'),('Kanagawa', '神奈川県'),('Niigata', '新潟県'),('Toyama', '富山県'),('Ishikawa', '石川県'),('Fukui', '福井県'),('Yamanashi', '山梨県'),('Nagano', '長野県'),('Gifu', '岐阜県'),('Shizuoka', '静岡県'),('Aichi', '愛知県'),('Mie', '三重県'),('Shiga', '滋賀県'),('Kyoto', '京都府'),('Osaka', '大阪府'),('Hyogo', '兵庫県'),('Nara', '奈良県'),('Wakayama', '和歌山県'),('Tottori', '鳥取県'),('Shimane', '島根県'),('Okayama', '岡山県'),('Hiroshima', '広島県'),('Yamaguchi', '山口県'),('Tokushima', '徳島県'),('Ehime', '愛媛県'),('Kochi', '高知県'),('Fukuoka', '福岡県'),('Saga', '佐賀県'),('Nagasaki', '長崎県'),('Kumamoto', '熊本県'),('Oita', '大分県'),('Miyazaki', '宮崎県'),('Kagoshima', '鹿児島県'),('Okinawa', '沖縄県')])
- 続いて、宣言したこれらテーブルを参照する形で、データ変換を定義していきます。intermediateディレクトリに、PV数、SS数、UU数を集計できるようpage_viewのイベントを抽出する定義を書きます。
※config.nameを明示的に定義しない場合は、ファイル名がテーブル名になります。
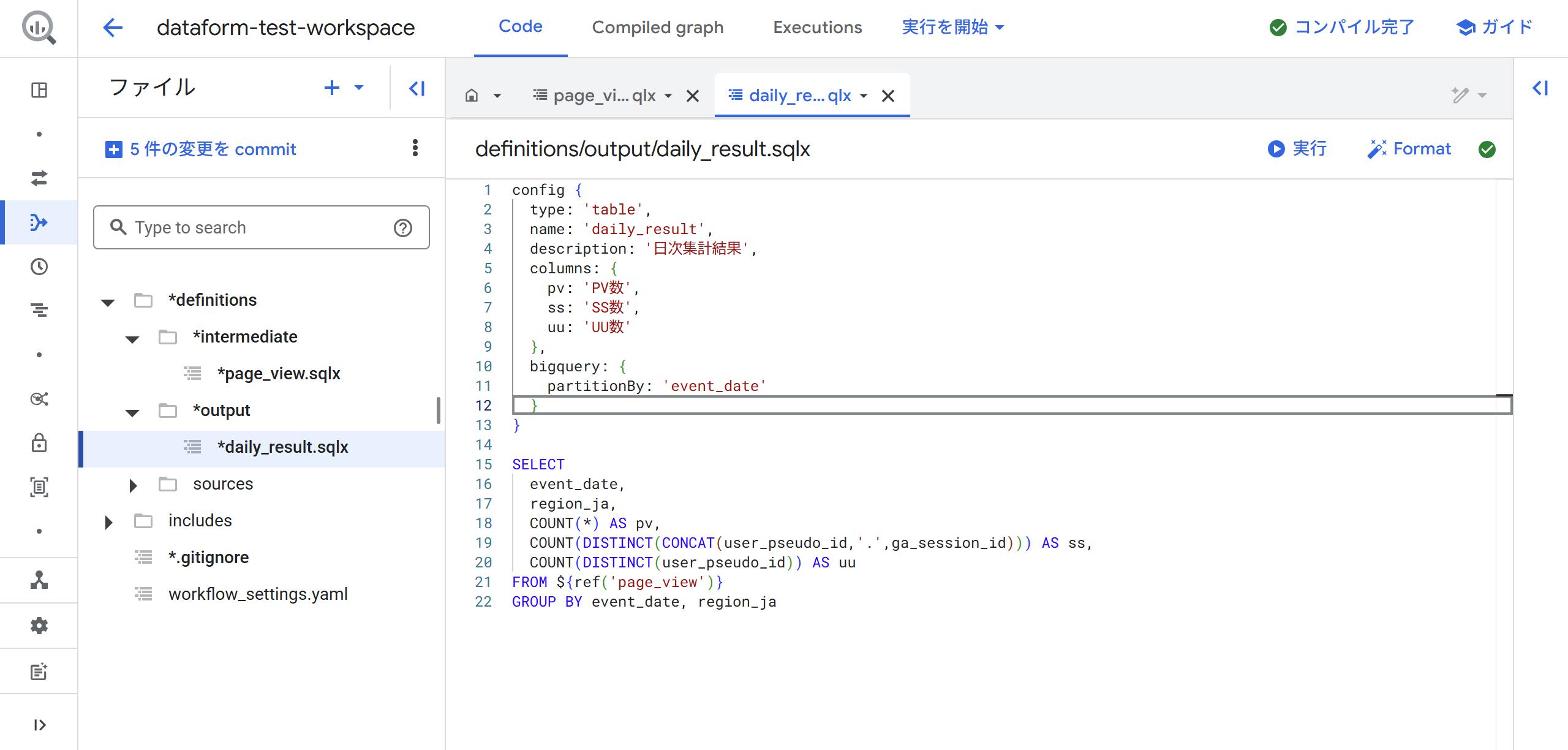
123456789101112131415161718192021222324252627282930313233343536373839404142config {type: 'table',name: 'page_view',description: 'PVイベントのログ',columns: {event_year_month: 'イベントの年月(JST)',event_date: 'イベントの日付(JST)',event_datetime: 'イベントの日付+時刻(JST)',user_id: 'ユーザーID',session_id: 'セッションID',page_title: 'ページタイトル',page_location: 'ページURL',region_en: '地域(英語)',region_ja: '地域(日本語)',device_category: 'デバイス種類',device_mobile_brand_name: 'モバイルデバイスのブランド名',device_mobile_model_name: 'モバイルデバイスの機種'},bigquery: {partitionBy: 'event_date'}}SELECTFORMAT_DATE('%Y-%m', DATE(TIMESTAMP_MICROS(e.event_timestamp), 'Asia/Tokyo')) AS event_year_month,DATE(TIMESTAMP_MICROS(e.event_timestamp), 'Asia/Tokyo') AS event_date,FORMAT_TIMESTAMP('%Y-%m-%d %H:%M:%S', TIMESTAMP_MICROS(e.event_timestamp), 'Asia/Tokyo') AS event_datetime,e.event_name,e.user_pseudo_id,(SELECT value.int_value FROM UNNEST(e.event_params) WHERE key = 'ga_session_id') AS ga_session_id,(SELECT value.string_value FROM UNNEST(e.event_params) WHERE key = 'page_title') AS page_title,(SELECT value.string_value FROM UNNEST(e.event_params) WHERE key = 'page_location') AS page_location,e.geo.region AS region_en,(CASE WHEN p.name_ja IS NOT NULL THEN p.name_ja ELSE e.geo.region END) AS region_ja,e.device.category AS device_category,e.device.mobile_brand_name AS device_mobile_brand_name,e.device.mobile_model_name AS device_mobile_model_nameFROM${ref('events_*')} eLEFT JOIN ${ref('prefectures')} pON e.geo.region = p.name_enWHERE e.event_name IN('page_view') - 中間テーブルができたら、日ごとにPV数、SS数、UU数を集計したテーブルmonthly_resultを作ります。以下のようなSQLXファイルをoutputディレクトリに作っていきます。
12345678910111213141516171819202122config {type: 'table',name: 'daily_result',description: '日次集計結果',columns: {pv: 'PV数',ss: 'SS数',uu: 'UU数'},bigquery: {partitionBy: 'event_date'}}SELECTevent_date,region_ja,COUNT(*) AS pv,COUNT(DISTINCT(CONCAT(user_id,'.',session_id))) AS ss,COUNT(DISTINCT(user_id)) AS uuFROM ${ref('page_view')}GROUP BY event_date, region_ja - これでデータ変換の記述は完了です。
⑤データ変換の実行
Dataformでは、SQLXファイルそれぞれがアクションと呼ばれ、任意のアクションを実行することができます。ここでは、上記で書いたアクション全てをまとめて実行してみましょう。
- 画面上中央の[実行を開始]ボタンを押して、[操作を実行]を押し、[ALL ACTIONS]を選んで下にある[実行を開始]ボタンを押します。そうすると[ワークフロー実行を作成しました。]というメッセージが表示されて実行が始まります。
- メッセージの横に[詳細]リンクがあるので、それを押すと実行状況を確認できます。以下のような形で、 実行したアクションの結果が順番に分かります。なお、実行順序はこちらで明記していませんが、refで定義した依存関係を考慮して自動的に適切な順序に組み立ててSQLを実行してくれています。便利ですね。
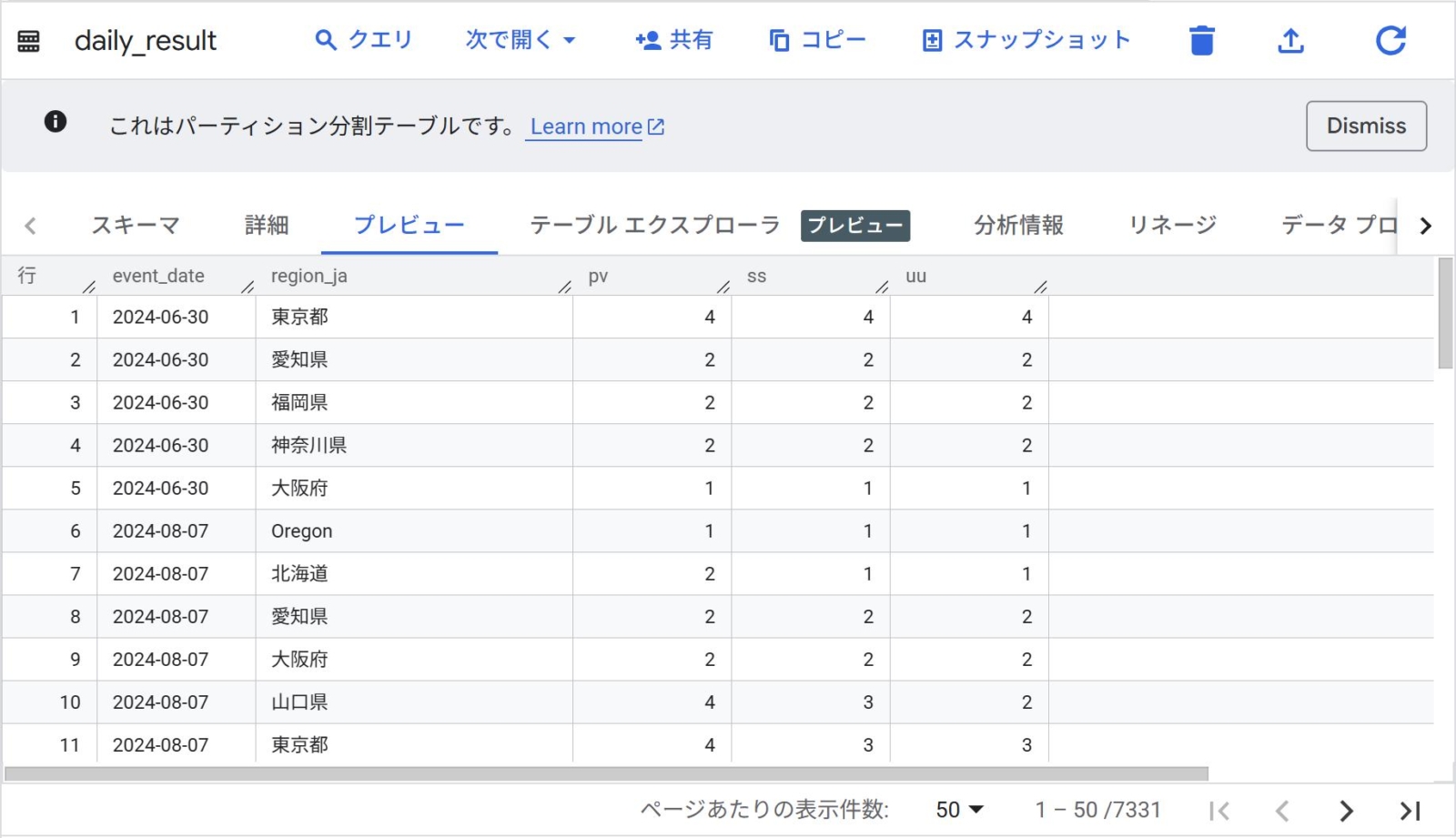
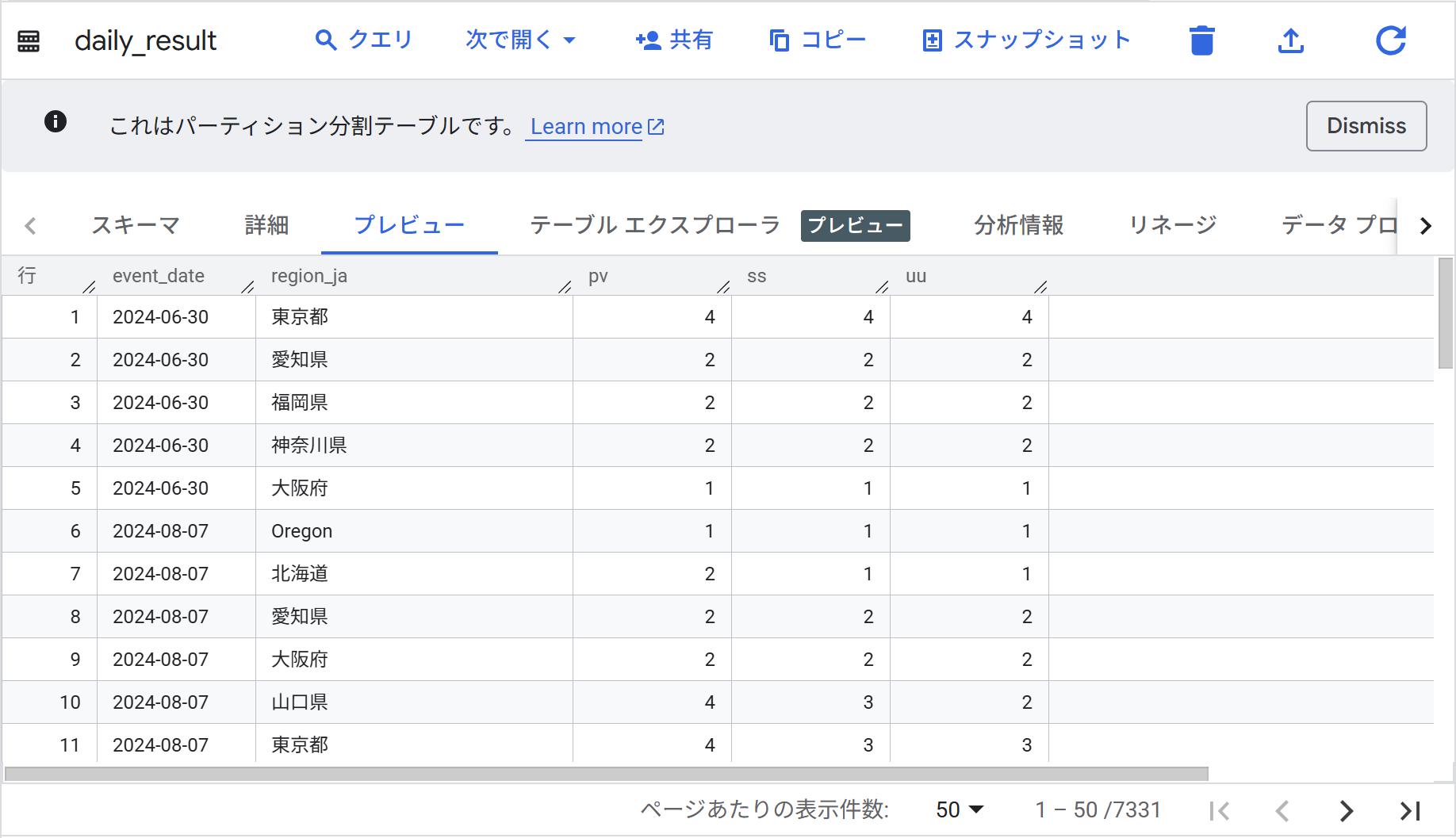
- 実行後、BigQueryのdataformデータセットにてテーブルが生成されていることを確認します。問題なく作れていればOKです。
なお、今回はそのまま全てのアクションを実行しましたが、それ以外の実行ももちろん可能です。[ALL ACTIONS]を選ぶところで分岐があり、
- [SELECTIONS OF ACTIONS] - 任意のアクションを実行する。。なお、依存関係や依存者を含めるかどうかの親切なオプションや、増分テーブルに対する完全更新のオプションもある。
- [SELECTIONS OF TAGS] - 任意のタグのついたアクションを実行する。なおタグは、SQLXファイルのconfigで設定できるので、複雑なワークフローを作る際は適宜な単位でタグをつけておくことが推奨。
- [ALL ACTIONS] - 全てのアクションを実行する。シンプル。
のように柔軟性高く実行することができます。
ちなみに、画面右にポツンと置かれている[実行]のボタンを押すとクエリを実行して結果をプレビューすることができるので、開発中にとりあえず実行したいときには便利です。
⑥データ変換の定期実行の設定
実務上は記述したデータ変換を定期的に実行する必要があるケースがほとんどです。今回のGA4のデータは日次実行でよいかなと思うので、毎朝6時の実行ということで設定していきます。
- ワークスペースの内容をリポジトリにコミットします。コミットできる内容がある場合は、画面右上あたりに[●件の変更をCOMMIT]というボタンがあるので押して、commitメッセージを書いた上で一番下の[すべてのファイルをCOMMIT]ボタンを押し、[ワークスペースは最新の状態です]と表示されていることを確認します。
- ワークスペースからリポジトリの方に戻り、[リリースとスケジュール]を押し、[製品版リリースの作成]ボタンを押します。
- [リリース構成を作成]という画面が開かれるので、リリースID、頻度、タイムゾーンを設定します。リリースIDはデフォルトのまま[production]、頻度は[なし]として、[作成]ボタンを押すと、リリース構成が作成されます。(※定期的に最新のデフォルトブランチをリリース構成に反映する場合は頻度を設定します。)
- このリリース構成に対して、実際のワークフロー構成を作ります。
ワークフロー構成の[作成]ボタンを押し、構成ID=[daily-schedule]、リリース構成=[production]、サービスアカウント=[デフォルトのDataformサービスアカウント]、頻度=[0 6 * * *]、タイムゾーン=[日本標準時(JST)]と設定し、対象アクションを[ALL ACTIONS]にして[作成]ボタンを押すと完了です。以下のようなスケジュールができます。
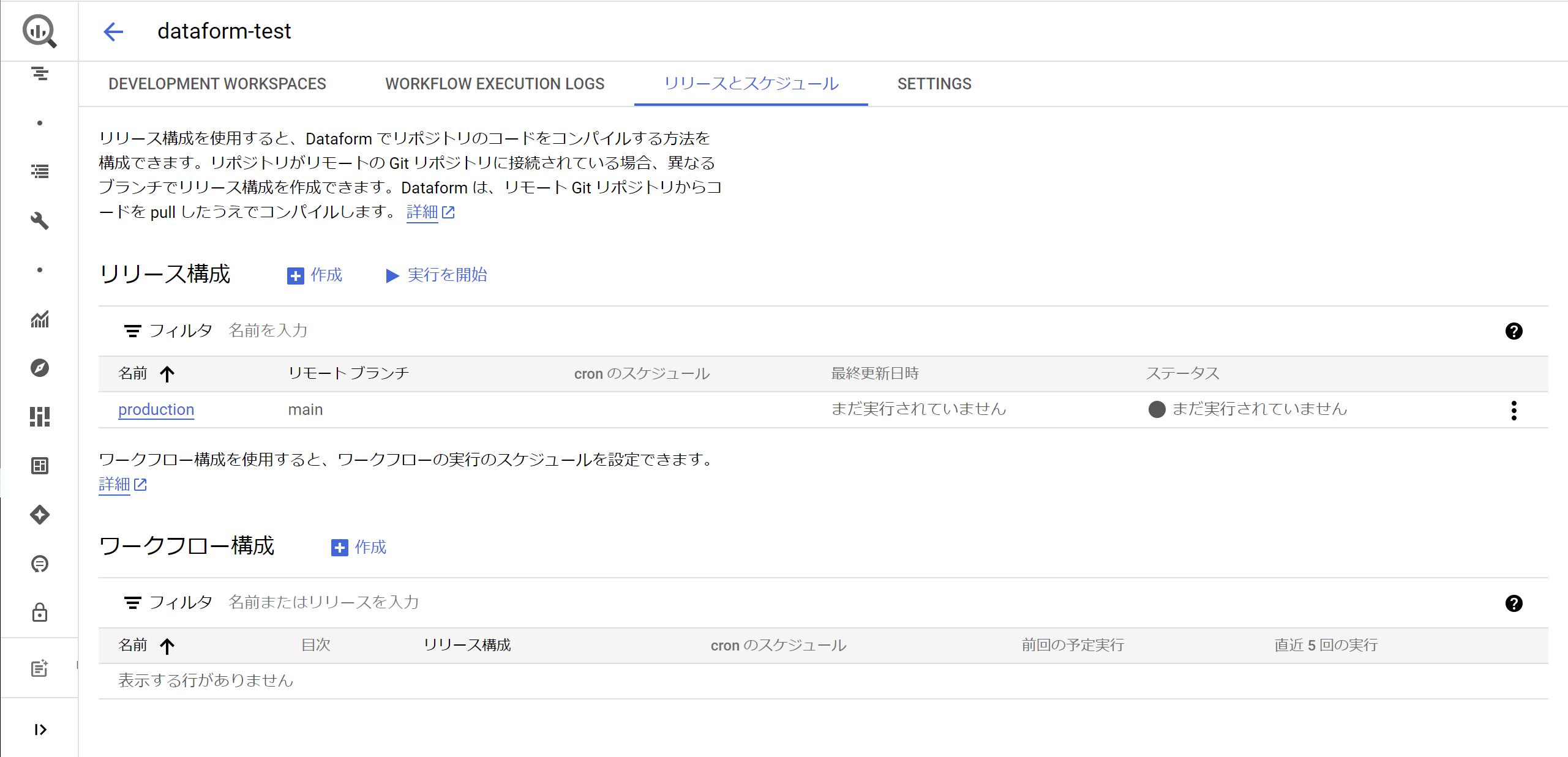

⑦Looker Studioでのデータ参照
最後に、Looker Studio側でデータを参照します。
- Looker Studioファイルにて[データを追加]から[BigQuery]を選び、今回作ったdataformデータセットのdaily_resultテーブルを設定します。なお、パーティション分割テーブルなので、設定の際は必ず[event_dateを期間ディメンションとして使用]にチェックを入れましょう。(忘れるとせっかくのパーティションが効かず、BigQueryの課金が増えかねません…)
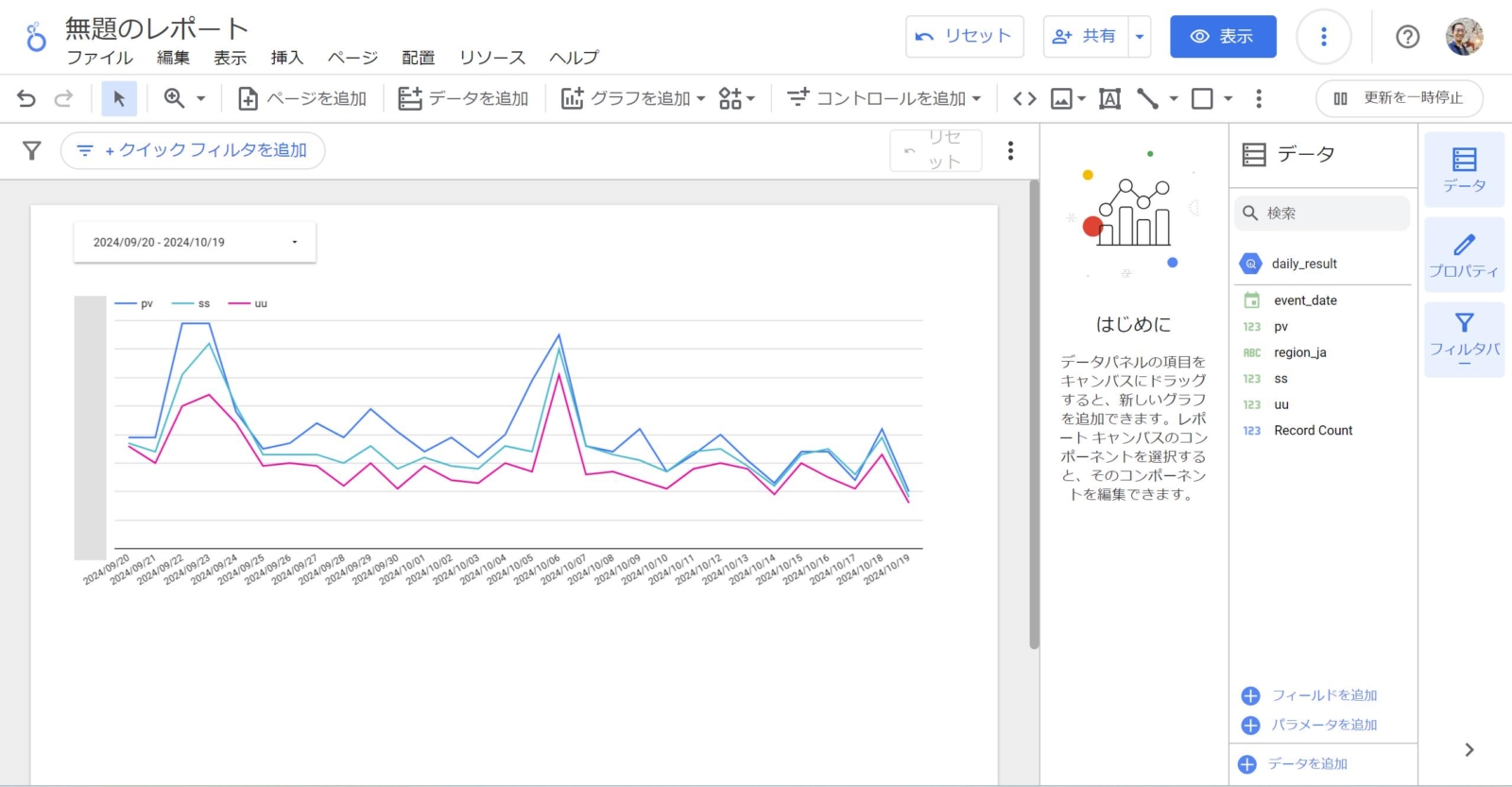
- データを追加できたら、あとは期間設定フィルターを置きつつ折れ線グラフにてpv,ss,uuを指標に、ディメンションにevent_dateを設定すると、日ごとの各種指標が見えるようになりました!
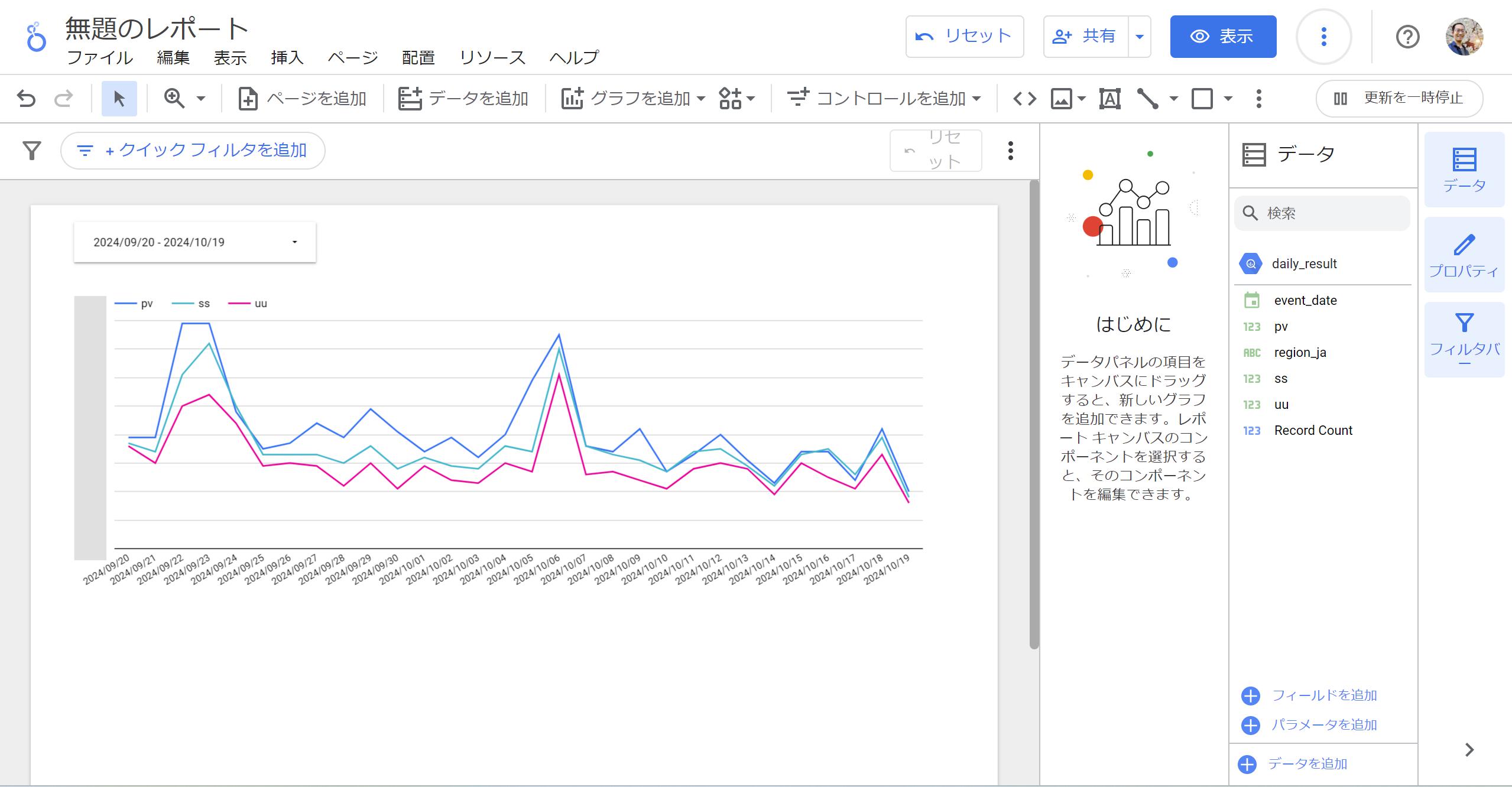
だいぶ長丁場になりましたが、この流れでDataformでのデータ変換からのLooker Studioでの可視化が可能です。
Dataformのそれ以外の特長は?
Dataformは非常に多機能であるため、上記の内容では基本的な処理しか説明できていません。それ以外で、個人的に便利だと感じた機能を箇条書きでまとめていきます。
1.クエリのスキャンデータサイズの事前把握
Dataform上でももちろんSQL実行前に処理されるデータ量が分かるようになっています。画面右カラムにある[コンパイル済みクエリ]を開くと「このクエリを実行すると、●MBが処理されます。」のように書いてあるので、BigQueryでお金を溶かさないよう、実行する前に必ず確認しておくようにしましょう。
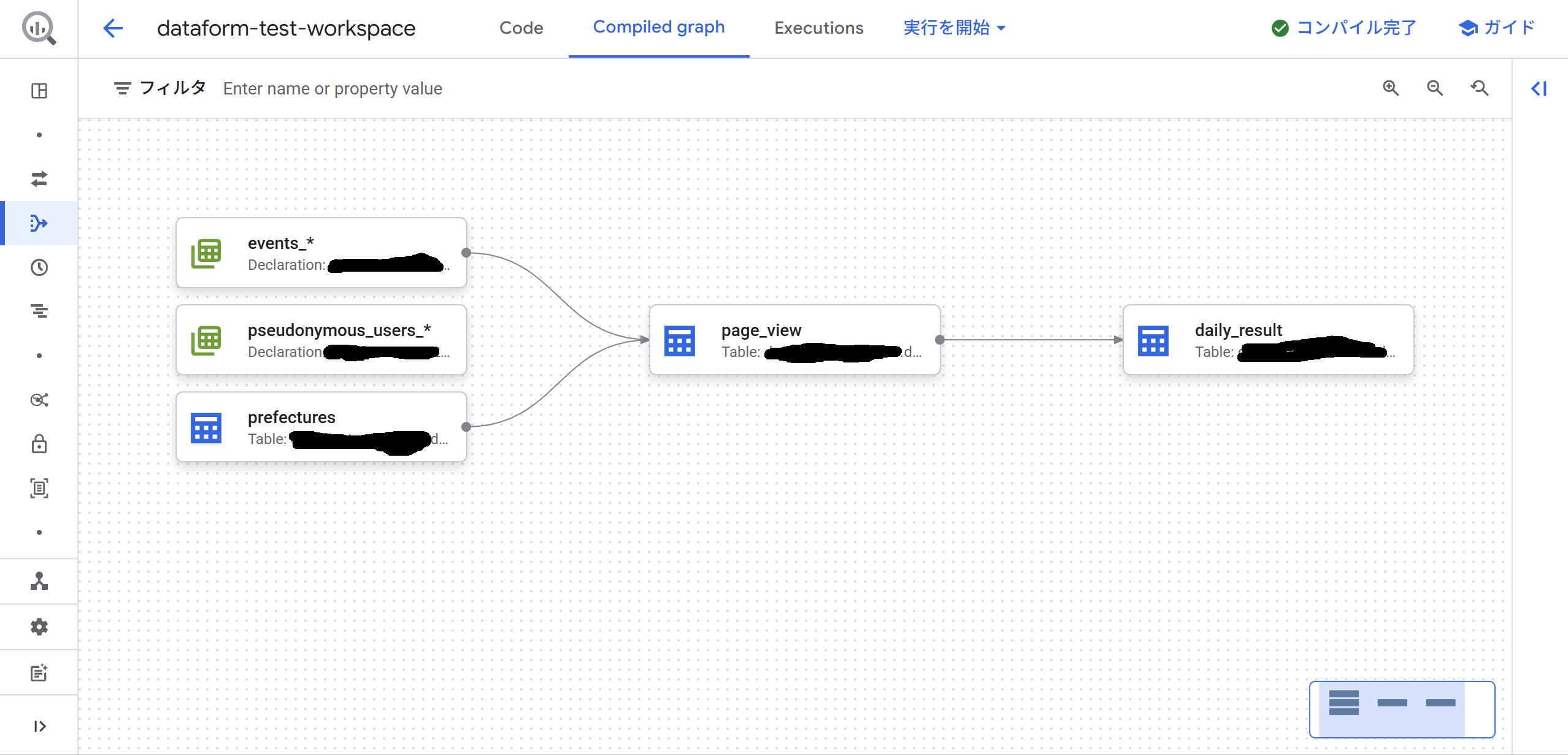
2.データリネージ機能(COMPILED GRAPH)
ちゃんとref機能を使ってSQLXファイルを書いていくと、以下のようなデータリネージが簡単に見られます。便利!
3.assertions機能
SQLXファイルのconfigにてassertionsを設定すると、データのバリデーションチェック(NULLがないとか、値がユニークであるとか)を簡単に設定することができます。チェックのためにわざわざSQLを書かなくて済むので便利です。詳しくは公式リファレンスを見ましょう。
4.増分テーブル機能
SQLXファイルのconfig.typeはいくつか種類があり、本例では既存テーブルを参照するdeclarationとテーブルを新規作成するtableを使いましたが、それ以外にincrementalという増分テーブルの定義もあります。いわゆる差分更新を得意とする定義のため、場所によってはシンプルかつ強力に実装できます。これも詳しくは公式リファレンスを見ましょう。なお注意事項として、この機能を使う場合は[Dataform 編集者]のロールが必要みたいなので注意しましょう。
5.カスタムSQL機能
SQLXファイルのconfig.typeの最後の種類にoperationsがあります。カスタムSQLという仰々しい名前ではありますが、要はcreate table以外の処理、例えばinsertやdelete, mergeなどを行うことが可能です。今回は使いませんでしたが、実務上は大活躍する機能になります。これも詳しくは公式リファレンスを見ましょう。
※カスタムSQLでテーブル生成する場合はconfig.hasOutput=trueを記述する必要があるなど儀式的な設定があるので注意すること。
6.includesファイルによる定数や構文の使い回し
よく使う定数や構文をライブラリ化して使い回すことができます。includesディレクトリに、例えばconstants.jpのようなファイルを作ってCURRENT_JSTパラメータを設定すると、SQLXファイルにて${constants.CURRENT_JST}と書くだけで長ったらしい現在時刻の値を呼び出せます。
|
1 2 3 |
module.exports = { CURRENT_JST: `DATETIME(TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL 9 HOUR))` }; |
なお注意点として、SQL文はシングルクォートもしくはバッククォートで囲む必要があります。
7.config.nameは省略できる
config.type=tableでは、config.nameを省略できます。省略した場合、ファイル名がそのままテーブル名になります。ファイル名=テーブル名は分かりやすいので、意識して省略していってもいいかもしれません。
逆に、それが何のテーブルなのかの説明は大事なので、config.descriptionは忘れずに書いておきたいところです。
Dataformの注意点は?
BigQueryでデータ変換するうえでとにかく便利なDataformですが、いろいろと注意点はあります。
1.ネットにある2,3年以上古い情報はダメかも…
Dataformは2024年10月時点でver3.0.0ですが、特にGoogle Cloudに取り込まれた2023年6月以降のアップデート(特に2024年6月のver3.0.0)で仕様変更が多くあるようです。ネットで探して出てくる2,3年以上古い情報は互換性がないものが散見されるので、注意しましょう。
2.BigQueryでお金を溶かさない…
Dataform自体は無料ですが、DataformがBigQueryをスキャンする際は費用がかかります。そもそも定期実行するDataformのデータ変換は何度も繰り返されることで費用がどんどん上がっていくリスクがあります。Google Cloudのコスト管理ツールで予算を設定して、予算を超えそうになったらアラートが飛ぶようにしておきましょう。
なお、ジョブの実行日と課金日は±1,2日のズレがあるようで、正直よくわからないところがあります。ざっくり見ていくようにしましょう。
3.差分処理を考える
BigQueryでお金を溶かさないうえで大事なのが差分処理です。
本記事では全データを対象に毎日集計をする実装にしていまして、小規模なサイトであればこれでも問題ないですが、大規模なアクセスのあるサイトのGA4では右肩上がりに増えるログデータに対してスキャン量も右肩上がりに増えていって、BigQuery費用がかさむようになる可能性があります。
その場合は、増分テーブル(config.type=incremental)を利用したり、差分処理をカスタムSQL(config.type=operations)で実装したりなどの工夫によって費用を抑え、かつデータ処理時間も抑えていくことを考えましょう。
4.型を厳密に定義しづらいものと考える
Dataformはその仕様上、データ型を厳密に定義することが得意ではありません。SQLXファイルでconfig.type=tableなどでテーブル作成する場合、列に対して定義できるのはdescriptionのみ。データ型は自動生成となります。
敢えて厳密に定義する場合は、config.type=operationsのカスタムSQLで敢えて書くことになるため、Dataformのシンプルな書き味というメリットが半減してしまいます。クリティカルになることは少ないかもですが、覚えておきましょう。
5.COMMITとリリース構成への反映を忘れずに
Dataformの開発ワークスペースでSQLXファイルを更新しても、定期実行には即座には反映されません。デフォルトブランチへのCOMMITと、リリース構成への反映をして初めて定期実行ワークフローに反映されます。最後まで反映を忘れないようにしましょう。
6.外部サービス連携ワークフローの検討
Dataformのワークフロー機能は自由度が高いのでだいたいのことはできますが、Dataformに閉じるので、それ以外のサービスとの連携をしたい場合はWorklowsやCloud Schedulerなど別サービスを利用する必要があります。詳しくは公式リファレンスを見ましょう。
まとめ
以上、「Dataformを使ってBigQueryにあるGA4データを加工してLooker Studioで可視化してみた話」ということでまとめてみました。
configやrefの使い方に若干の癖がありますが、Google Cloudに閉じてシンプルにデータパイプラインを構築できるので、覚えられればかなり強力なツールになるでしょう。
以上、この記事が誰かの参考になれば幸いです。





